Radical-level Ideograph Encoder for RNN-based Sentiment Analysis of Chinese and Japanese
1. どんなもの?
漢字を構成する部首レベル(Radical-level)の特徴から、CNNおよびBi-directional RNNを用いて少ないパラメータ数で文書分類を行うモデルを提案している。
2. 先行研究と比べてどこがすごいの?
単語の埋め込み表現はNLPのタスクにおいて幅広く利用されているが、規模の大きなボキャブラリはモデルの学習の際にコストとなる。先行研究では文字レベルの特徴を用いることでモデリングを行っているものがあるが、日本語や中国語における文字のボキャブラリは、英語のアルファベットと比べて非常に大きい。
本研究では日本語や中国語で用いられている漢字に注目し、それらを構成する部首等を分解して利用するRadical-levelの特徴を利用したアーキテクチャとなっている。Radical-levelの特徴を用いることでWord-levelより90%程度小さいボキャブラリで、なおかつ先行研究と比べてとても少ないパラメータ数で同程度の精度を達成している。
3. 技術や手法の”キモ”はどこにある?
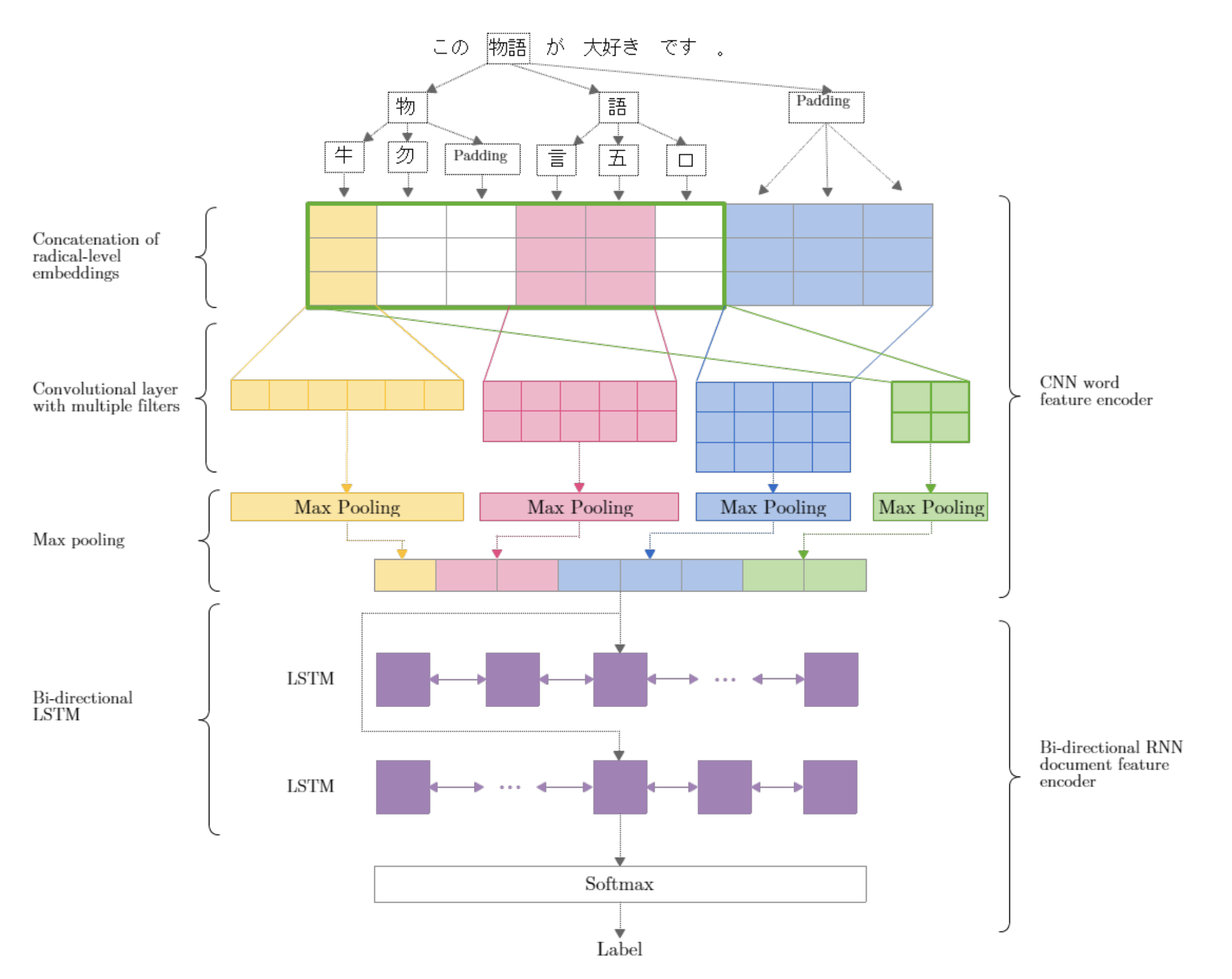
- 先行研究(Kim+ 2016)のモデルと似ているアーキテクチャを採用
- 異なる点はCharacter-levelの特徴の代わりにRadical-levelの特徴を利用している
- Highway layerは利用していない
- [Kim+ 2016]ではHighway layerを利用し、精度を上げている
- しかしながら本アーキテクチャでは精度向上にあまり寄与しなかったため、今回は採用していない
- N Radical-level Embeddings
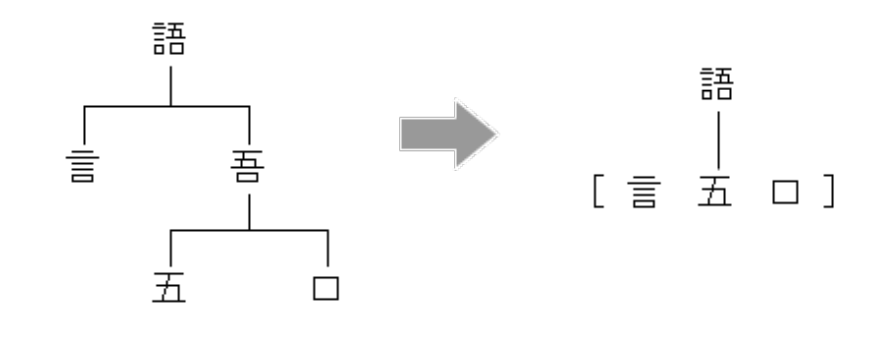
- 各文字に対して、”部首”や”つくり”に分解した文字表現であるRadical-level Embeddingsを用いる
- Radical-level Embeddingsが固定長になるようにゼロパディングを行っている
- CNNエンコーダを用いた文字Radicalから単語表現の獲得
- 複数サイズのカーネルで複数種類の特徴を抽出
- stride=1でRadical-levelの特徴を抽出する
- stride=nでCharacter-levelの特徴を抽出する
- Bi-directional LSTMエンコーダを用いた単語表現から文書表現の獲得
4. どうやって有効だと検証した?
中国語のレビューデータセットであるCtripと日本語のレビューデータセットであるRakutenレビューデータセットを用いてベースラインと提案モデルの精度を比較している。各レビューデータセットに付与されている6ポイントの評価を3ポイント以上をpositive、それ以下をnegativeとして感情分析タスクとして評価を行っている。
ベースラインのモデルと比較して、Character-level embeddingsモデルより13%程度少ないパラメータ数で、Word-level embeddingsモデルより90%程度少ないパラメータ数で先行研究のモデルと同程度の精度を出していることが分かる。
5. 議論はあるか?
- 小さいボキャブラリ数、少ないパラメータ数で効率の良い学習が可能
- CNNエンコーダは効果的である
- 本アーキテクチャではHighway layerはあまり効果がなかった
- 本実験で行った2クラスの感情分析タスクの場合、CNNエンコーダとBi-directional RNNエンコーダ間の全結合層を必要としないため、Highway networkは常に入力を出力に渡すよう学習していると考えられる
6. 次に読むべき論文はあるか?
本研究のベースとなるアーキテクチャについて
- The character-aware neural language model
- Bi-directional RNN
- Hierarchical attention networks
- FastText