Few-Shot Adversarial Domain Adaption
1. どんなもの?
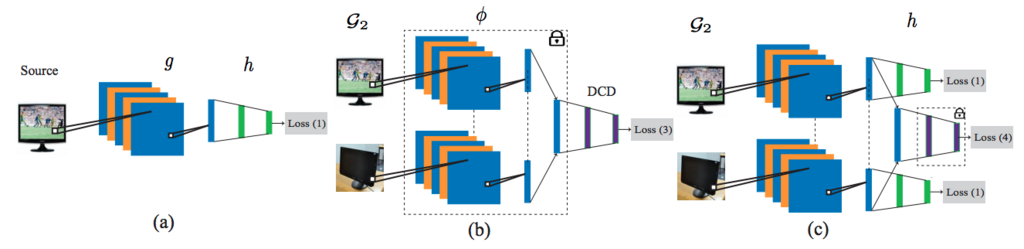
本研究ではDeepモデルを用いた教師ありのドメイン適応の問題に対して対処するフレームワークを提案している。主なアイディアは埋め込み表現を学習する際にAdversarialな学習を導入し、2つの異なるドメインの特徴を保持するように埋め込みつつ、同時に埋め込み表現が意味をなすように配置させるところである。教師ありタスクの場合、一般的には大量のラベル付与済みデータが必要であるが、ラベルを付与すべきデータが少なく済むことでより扱いやすい問題となる。こういったFew-shotな学習の場合にデータ欠損があると、埋め込み空間に対して埋め込み表現の配置と分離というのは困難を極める。
提案モデルでは典型的な2値のAdversarial discriminatorが4つの異なるクラスを分離するためにData augmentationに工夫することで、教師ありのドメイン適応問題対して有効であることを見つけている。加えて本手法ではラベル付与済みデータがとても少ない場合、特にカテゴリあたり1サンプルであったとしても高速に適応できていることが示されている。MNISTやSVHNデータセット等を用いて本手法のドメイン適応の効果を確認している。