Tell Me Where to Look: Guided Attention Inference Network
1. どんなもの?
Attention map を用いた弱教師ありセマンティックセグメンテーションを高精度に行う guided attention inference networks (GAIN) を提案。
2. 先行研究と比べてどこがすごいの?
クラスラベルをもとに学習し予測することで得られる attention map は局所的な特徴やセグメンテーションの情報を保持している場合が多い。 こうした attention map を利用しセマンティックセグメンテーションといったタスクを解く弱教師あり学習 (weakly supervised learning) の枠組みは先行研究で複数手法が提案されてきた。 しかしながらクラスラベルから classification loss で学習した attention map は分類に必要最低限の領域にのみフォーカスしており、対象となる物体全体をカバーすることは難しい。
また学習データセットのバイアスにより、未知のデータに対して正しくセグメンテーションを行うのは難しい。
具体的にはボートと海は同時に撮影される場合が多く、高い相関がある。
したがって予測時に海面が移っていないボートのサンプルを正しくセグメンテーションするのは難しい場合が多い。
本研究では end-to-end で attention map を学習し、classification loss に加えて attention の妥当性を考慮する loss を同時に学習する guided attention inference networks (GAIN) を提案している。
3. 技術や手法の”キモ”はどこにある?
GAIN
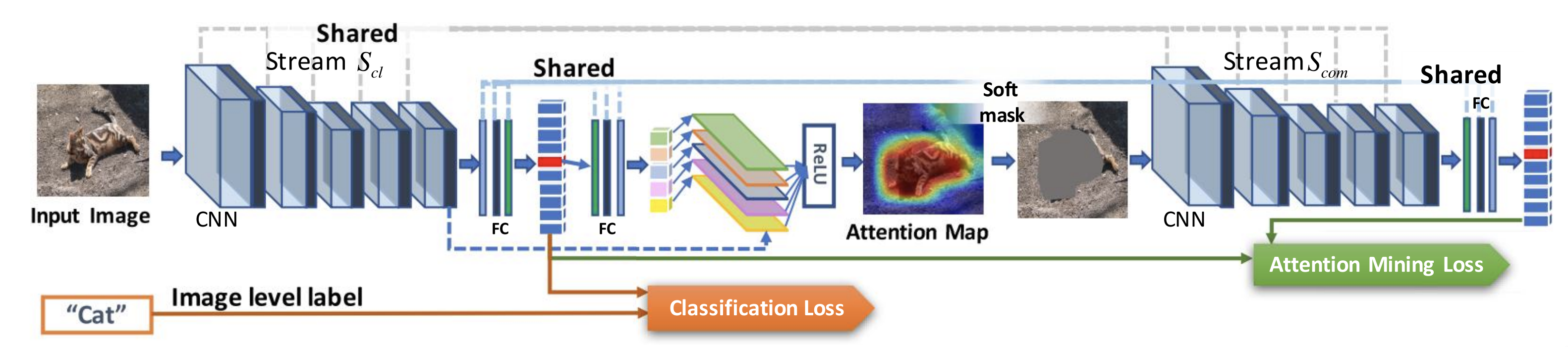
- 共通する 2 つのストリーム ( と )
- 2 つのストリームにおける conv 層と一部の fc 層のパラメータは共通
- Classification stream
- クラスに分類するために役立つ領域を見つけるよう学習
- マルチラベル・マルチクラスの
classification lossを最小化する
- Attention mining stream
- クラスの決定に寄与する可能性があるすべての領域が attention に含まれるよう学習
- 対象クラスに対する attention 領域が大きくならないようにする
attention mining lossを最小化する
GAIN
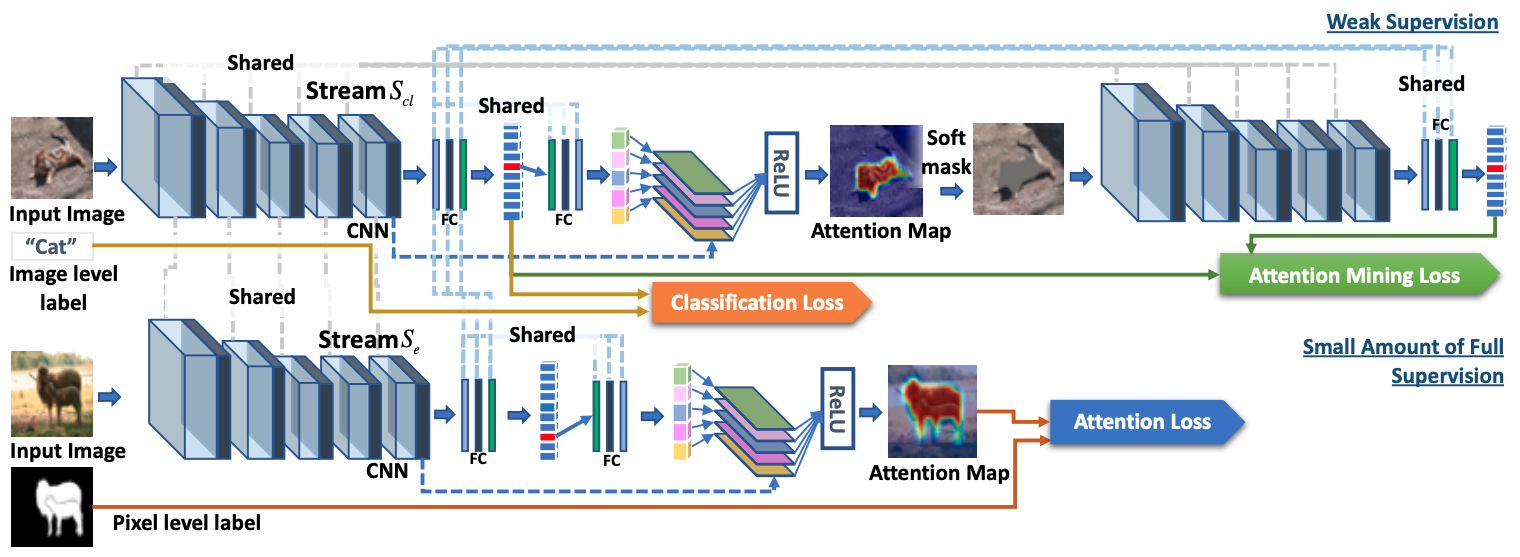
- 追加で小規模のセグメンテーションマスクを学習に利用
- External stream を追加
- 教師となるセグメンテーションマスクから attention map を学習
- Attention map とセグメンテーションマスクの二乗誤差である
attention lossを最小化する
- External stream を追加
4. どうやって有効だと検証した?
PASCAL VOC を用いた弱教師ありセグメンテーションタスクで先行研究の SoTA モデルとの mean intersection-over-union (mIoU) のスコアを比較している。 SoTA モデルである SEC に対して attention map を用いた提案手法を適用することにより精度向上が確認されている。
5. 議論はあるか?

SoTA モデルである SEC に対して GAIN を導入することにより、複数物体を正確に広い範囲で捉えることが可能となっている。 また追加でセグメンテーションマスクを用いることで、より精度のよいセグメンテーションが行われている。

学習データセットにバイアスがある場合にベースラインの Grad-CAM と提案手法の GAIN がどのような予測をするか可視化を行った結果。
Grad-CAM は海とともに現れやすいボートに過学習している傾向があるが、GAIN はボートを適切に捉えていることがわかる。
提案手法の GAIN がバイアスのあるデータセットに対してもロバストであることを示している。