Learning Chinese Word Representations From Glyphs Of Characters
1. どんなもの?
漢字の文字画像からConvolutional AutoEncoder(convAE)を利用して文字表現を獲得し,その文字表現を用いた中国語の単語表現を獲得する手法を提案している.
2. 先行研究と比べてどこがすごいの?
先行研究における単語の分散表現の学習はCBOWやSkipgram,GloVeといったものがある.また中国語における単語の分散表現の学習は「漢字」の形状的特徴を活用する,Character-enhanced word embedding(CWE)やMulti-granularity Embedding(MGE)といったものが提案されている.
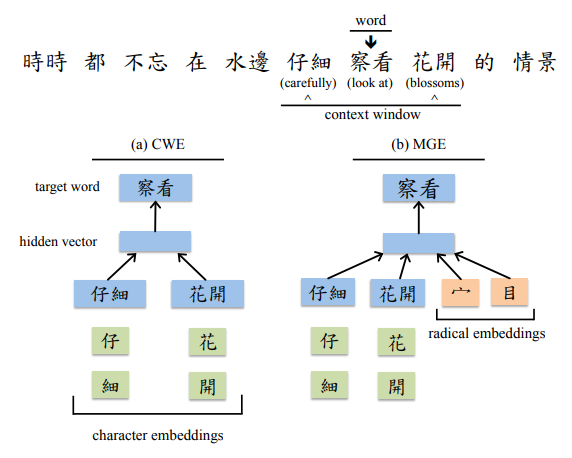
本研究ではCWEやMGEといった先行研究と同様に,漢字の形状に着目し文字の形状情報を抽出したのち,単語表現の学習に利用する2つの手法を提案している.
3. 技術や手法の”キモ”はどこにある?
- 文字表現の獲得
- 漢字の形状的特徴を考慮した文字表現を抽出するconvAE
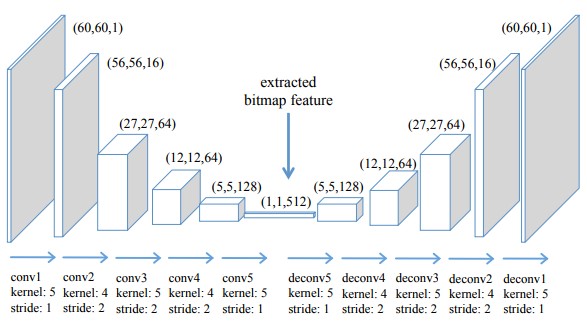
- 漢字の形状的特徴を考慮した文字表現を抽出するconvAE
- 単語表現の獲得
- Glyph-Enchanced Word Embedding(GWE)
- Enhanced by Context Word Glyphs(ctxG)
- 文字表現を組み合わせた単語表現ctxGからターゲット単語の表現を学習する
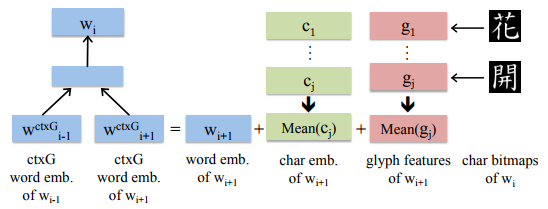
- 文字表現を組み合わせた単語表現ctxGからターゲット単語の表現を学習する
- Enhanced by Target Word Glyphs(tarG)
- ターゲット単語の文字表現の平均値を用いてターゲット単語の表現を学習する
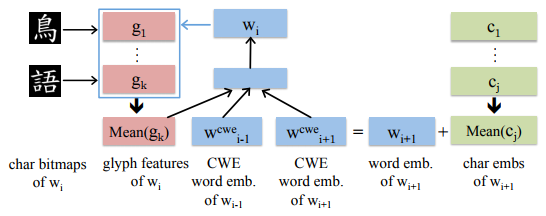
- ターゲット単語の文字表現の平均値を用いてターゲット単語の表現を学習する
- Enhanced by Context Word Glyphs(ctxG)
- Directly Learn From Character Glyph Features
- RNN-Skipgram
- GRUを用いて直接文字表現を並べた単語からターゲット単語の表現を学習する
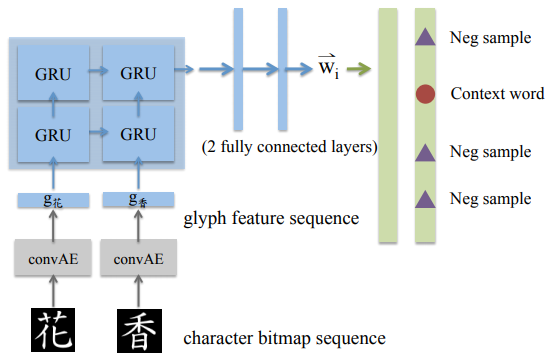
- GRUを用いて直接文字表現を並べた単語からターゲット単語の表現を学習する
- RNN-GloVe
- ターゲット単語と異なる単語を用いて共起からターゲット単語の表現を学習する
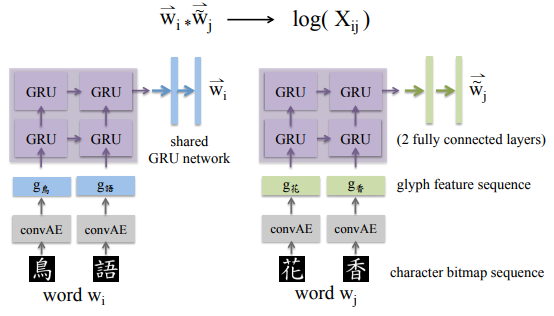
- ターゲット単語と異なる単語を用いて共起からターゲット単語の表現を学習する
- RNN-Skipgram
- Glyph-Enchanced Word Embedding(GWE)
4. どうやって有効だと検証した?
提案手法で学習した単語表現を用いて,単語の類似度,単語の類推タスクを行っている.
学習した文字表現をt-SNEを用いて2次元まで落とし,可視化したものが以下のようになっている.形状の似ている漢字が集まっていることが分かる.

5. 議論はあるか?
- 単語の類似度を検証する際に利用したデータセットであるWordSim-240とWordSim-296,SimLex-999は英語から中国語に翻訳したものを利用しており,翻訳したデータセットは公開している.
6. 次に読むべき論文はあるか?
CWEについて
MGEについて