Aggregated Residual Transformation for Deep Neural Networks
1. どんなもの?
入力に対し”cardinality”を元に様々な変換処理を施し,それらを集約するブロックを重ねることでハイパーパラメータを減らしたResNeXtを提案.ILSVRCでは2位という成績を残した.
2. 先行研究と比べてどこがすごいの?
VGGやResNetといったネットワークは同じ形状のブロックを複数重ねることでハイパーパラメータを減らすことができている.ResNeXtではこれらのブロックで入力に対し変換処理とembeddingの集約を行うことで,同一のトポロジを維持している.
また本研究では”cardinality”と呼ばれる変換処理のサイズを定義している.先行研究のResNet-50と同等の演算量を維持しつつcardinalityを増やすことで,画像分類の精度を向上させることができている.加えてcardinalityがネットワークの深さや幅より重要な要素であることを実験結果を元に主張している.
3. 技術や手法の”キモ”はどこにある?
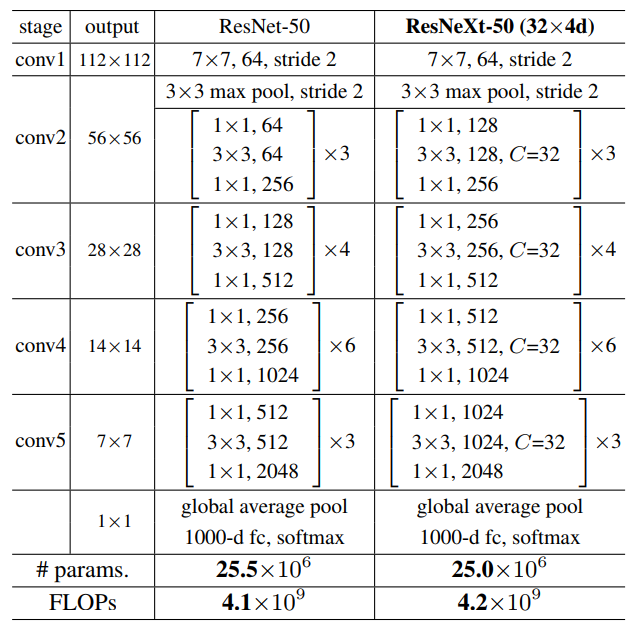
- VGG/ResNetライクなブロック構成で同一トポロジの維持とハイパーパラメータの削減を行う.
- ブロックは同じトポロジを有している.
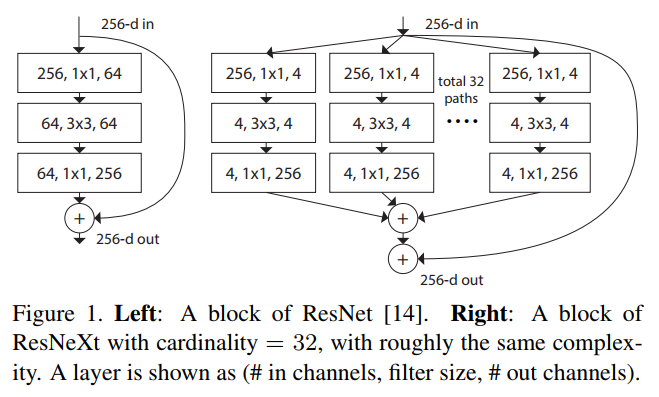
- ブロック構造の2つのルール
- 同じサイズのマップを出力するブロックでは,幅やフィルタサイズといったハイパーパラメータを共通化する.
- マップが1/2にダウンサンプリングされた場合は,ブロックの幅を2倍にする.
- ブロックは同じトポロジを有している.
- シンプルなニューロンで行われる重みと入力の積をそれぞれ足し合わせた集約を行うが,ResNeXtブロックではこの変換と集約を一般化している.
- 変換処理のサイズとして”cardinality”を定義している.cardinalityはより複雑な変換処理の回数をコントロールしており,ネットワークの幅や深さよりも効果的なパラメータとなっている.
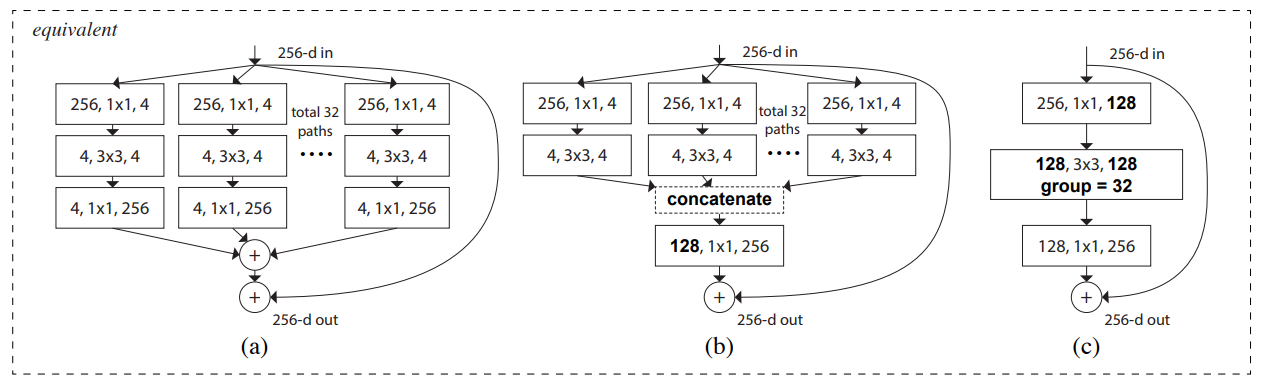
- Fig 1(右) のResNeXtブロックは Fig 3(b)や(c) と等価である.
- Fig 3(b) のResNeXtブロックはInception-ResNetブロックに似た構造をしているが,ResNeXtブロックはすべてのパスにおいて同一のトポロジを共有している.
- Fig 3(c) のようにGrouped Convolutionを用いることでResNeXtブロックを簡潔に記述することができる.
4. どうやって有効だと検証した?
ImageNet-1/ImageNet-5K,CIFAR-10/CIFAR-100,COCO object detection setを利用し,ResNet-50/100をベースラインとしてResNeXt-50およびResNeXt-101の精度を比較している.各データセットでResNeXt-50・ResNeXt-100がベースラインよりよい精度を記録している.
より層を深くしたResNet-200とResNeXt-101を比較した場合においても提案手法のResNeXt101がよいスコアを出している.
より幅を広くしたWide ResNetと同等のモデルサイズであるResNeXt-29を比較したところ,ResNeXt-29がよいスコアを出している.
5. 議論はあるか?
- 実装の詳細について
- ImageNet-1K/ImageNet-5K
- fb.resnet.torch をベースに実装
- 入力画像は拡大縮小およびaspect ratio augmentationを使用し,リサイズしたのちランダムに224x224サイズにクロップした画像を使用
- conv3, 4, 5のダウンサンプリングは,各ステージの最初のブロックでstride 2の3x3畳み込みで実行
- バッチサイズは256で8GPU上で学習を実行(GPUあたりバッチサイズ32)
- SGDを使用し,momentumは0.9
- Weight decayは0.0001に設定
- 学習率は0.1から開始し,3度学習率*0.1する
- He+2015に従ったweight initialization
- error率の評価時には短辺が256になるようリサイズし,224x224を中心からクロップ
- 今回使用したアーキテクチャは Fig 3(c) のものである.Fig 3のアーキテクチャすべてで同様の結果が得られるが,簡潔でより高速な Fig 3(c) のアーキテクチャを使用
- CIFAR
- ゼロパディングした40x40をフリップ処理したのちランダムに32x32にクロップした画像を使用
- 最初の層はフィルタ数64の3x3畳み込み層
- 3つのステージがあり,それぞれResNeXtブロックが3つ.各ステージの出力マップサイズ各32,16,8
- global average poolngから全結合層へと接続
- バッチサイズは128で8GPU上で学習を実行
- Weight decayは0.0005
- SGDを使用し,momentumは0.9
- 学習率は0.1から開始し,300epochのうち150epochと225epochで学習率を下げる
- ImageNet-1K/ImageNet-5K
- cardinalityとbase widthについて
- ブロック構造の2つのルールを適用するため,cardinalityとそれに伴うbase widthの関係は以下のようになる.

- ネットワークの層をより深くする/より広くするより,cardinalityを増やすほうが精度が良くなっている.
- ブロック構造の2つのルールを適用するため,cardinalityとそれに伴うbase widthの関係は以下のようになる.
6. 次に読むべき論文はあるか?
ResNetについて
Wide ResNetについて
Weight initializationについて