Class-Balanced Loss Based on Effective Number of Samples
1. どんなもの?
Long-tail な不均衡データに対して、各クラス数の分布を適切に考慮した class-balanced loss を提案。
2. 先行研究と比べてどこがすごいの?
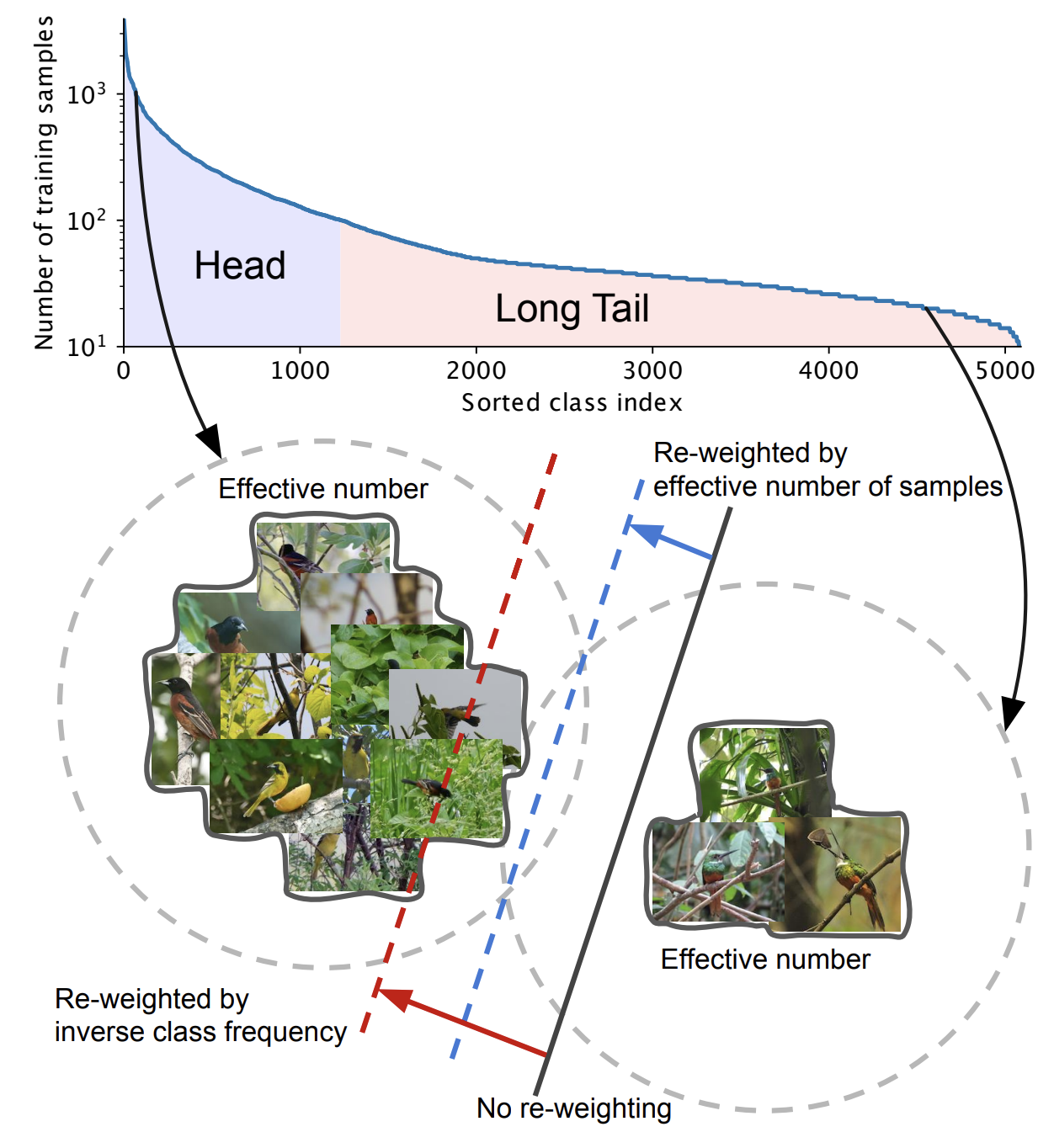
実世界のデータセットは long-tail な分布を持つ不均衡データであることが多い。
こうした不均衡データに対して、先行研究では主に re-sampling と cost-sensitive learning の観点から解決が図られてきた。
Re-sampling における over-sampling では学習時に重複したデータを学習して過学習を引き起こしたり、under-sampling では学習に重要なデータを適切にサンプリングして学習することが難しい。
そこで深層学習の文脈では損失関数に重み付けを行う cost-sensitive learning を採用する場合が多いが、こうした手法は実世界の long-tail な分布を持つ不均衡データに対してパフォーマンスが低下してしまう場合が多い。
本研究では long-tail な不均衡データに対して、対象となるデータ数に効果的な class-balanced loss を提案し、
一般的に広く使われている softmax cross-entropy や sigmoid cross-entropy、focal loss などに適用し効果の検証を行っている。
3. 技術や手法の”キモ”はどこにある?
Class-balanced loss
各クラス数に反比例する重み係数を導入することによって、long-tail な不均衡データに対しても効率的に学習するよう損失関数を定義した。
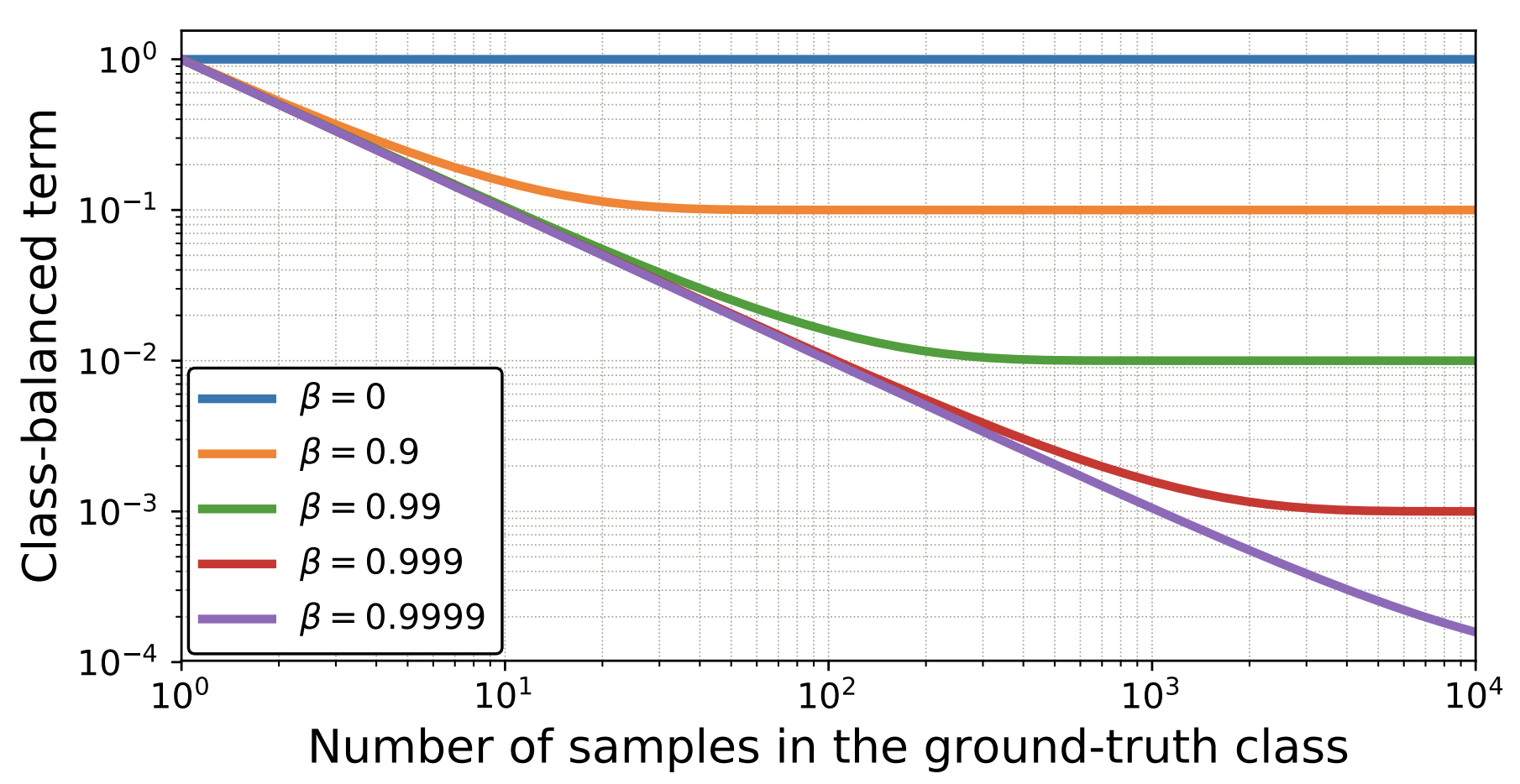
Class-balanced loss を一般的な損失関数に適用した場合は以下の通りになる。
- Class-balanced softmax cross-entropy
- Class-balanced sigmoid cross-entropy
- Class-balanced focal loss
4. どうやって有効だと検証した?
CIFAR10/100 に対して imbalanced factor を元にデータの分布を擬似的に不均衡にした long-tailed CIFAR10/100 、iNatiralist 、ImageNet を用いて、ベースラインのモデルと class-balanced loss を導入したモデルの比較を行っている。
Sigmoid ベースの loss を用いる場合は、最終全結合層のバイアスに対してクラスの事前確率を として、 として初期化し、バイアス項にのみ weight decay を適用している。
5. 議論はあるか?
画像認識タスクでは主に softmax cross-entropy が用いられるが、バイアス項を適切に初期化した sigmoid cross-entropy や focal loss が softmax cross-entropy を凌駕する結果を示した。
Class-balanced loss のハイパーパラーメタである は CIFAR-10 の場合 であったが、CIFAR-100 の場合は imbalanced factor ごとに異なる の設定が必要であった。
6. 次に読むべき論文はあるか?
Re-sampling ベースの手法
- Shen, Li, Zhouchen Lin, and Qingming Huang. “Relay backpropagation for effective learning of deep convolutional neural networks.” European conference on computer vision. Springer, Cham, 2016.
- Geifman, Yonatan, and Ran El-Yaniv. “Deep active learning over the long tail.” arXiv preprint arXiv:1711.00941 (2017).
- Buda, Mateusz, Atsuto Maki, and Maciej A. Mazurowski. “A systematic study of the class imbalance problem in convolutional neural networks.” Neural Networks 106 (2018): 249-259.
- Zou, Yang, et al. “Domain adaptation for semantic segmentation via class-balanced self-training.” arXiv preprint arXiv:1810.07911 (2018).
- Drummond, Chris, and Robert C. Holte. “C4. 5, class imbalance, and cost sensitivity: why under-sampling beats over-sampling.” Workshop on learning from imbalanced datasets II. Vol. 11. Washington, DC: Citeseer, 2003.
- Chawla, Nitesh V., et al. “SMOTE: synthetic minority over-sampling technique.” Journal of artificial intelligence research 16 (2002): 321-357.
Cost-Sensitive Learning ベースの手法
- Ting, Kai Ming. “A comparative study of cost-sensitive boosting algorithms.” In Proceedings of the 17th International Conference on Machine Learning. 2000.
- Khan, Salman H., et al. “Cost-sensitive learning of deep feature representations from imbalanced data.” IEEE transactions on neural networks and learning systems 29.8 (2018): 3573-3587.
- Sarafianos, Nikolaos, Xiang Xu, and Ioannis A. Kakadiaris. “Deep imbalanced attribute classification using visual attention aggregation.” Proceedings of the European Conference on Computer Vision (ECCV). 2018.
Importance sampling
決定境界を一定に調整
クラス数の逆数で重み付け
- Wang, Yu-Xiong, Deva Ramanan, and Martial Hebert. “Learning to model the tail.” Advances in Neural Information Processing Systems. 2017.
- Huang, Chen, et al. “Learning deep representation for imbalanced classification.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
クラス数の逆数の平方根で重み付け
- Mikolov, Tomas, et al. “Distributed representations of words and phrases and their compositionality.” Advances in neural information processing systems. 2013.
- Mahajan, Dhruv, et al. “Exploring the limits of weakly supervised pretraining.” Proceedings of the European Conference on Computer Vision (ECCV). 2018.
難しいサンプルにフォーカスして学習
- Freund, Yoav, and Robert E. Schapire. “A decision-theoretic generalization of on-line learning and an application to boosting.” Journal of computer and system sciences 55.1 (1997): 119-139.
- Malisiewicz, Tomasz, Abhinav Gupta, and Alexei A. Efros. “Ensemble of exemplar-SVMs for object detection and beyond.” Iccv. Vol. 1. No. 2. 2011.
- Dong, Qi, Shaogang Gong, and Xiatian Zhu. “Class rectification hard mining for imbalanced deep learning.” Proceedings of the IEEE International Conference on Computer Vision. 2017.
- Lin, Tsung-Yi, et al. “Focal loss for dense object detection.” Proceedings of the IEEE international conference on computer vision. 2017.
ノイジーなデータやラベルミスなデータにフォーカスして学習
- Koh, Pang Wei, and Percy Liang. “Understanding black-box predictions via influence functions.” Proceedings of the 34th International Conference on Machine Learning-Volume 70. JMLR. org, 2017.
- Ren, Mengye, et al. “Learning to reweight examples for robust deep learning.” arXiv preprint arXiv:1803.09050 (2018).