Content-Based Citation Recommendation
1. どんなもの?
メタデータに依存しない論文内容に基づいた、学術論文の草案に対する引用文献の推薦システムの提案。
2. 先行研究と比べてどこがすごいの?
既存の引用文献レコメンドシステムは著者の名前や出版社・学会名等のメタデータに依存している場合が多かった。 こうしたメタデータはレビュー時であったり草案時には利用が難しい。
本研究では既存の研究と異なり、論文内容に基づいて引用候補を識別するために使用したベクトルと同じ空間に埋め込み、 再学習が不要なモデルの構築が可能となる。 また計算の効率がよく、学習時・予測時にスケーラブルなモデルである。
3. 技術や手法の”キモ”はどこにある?
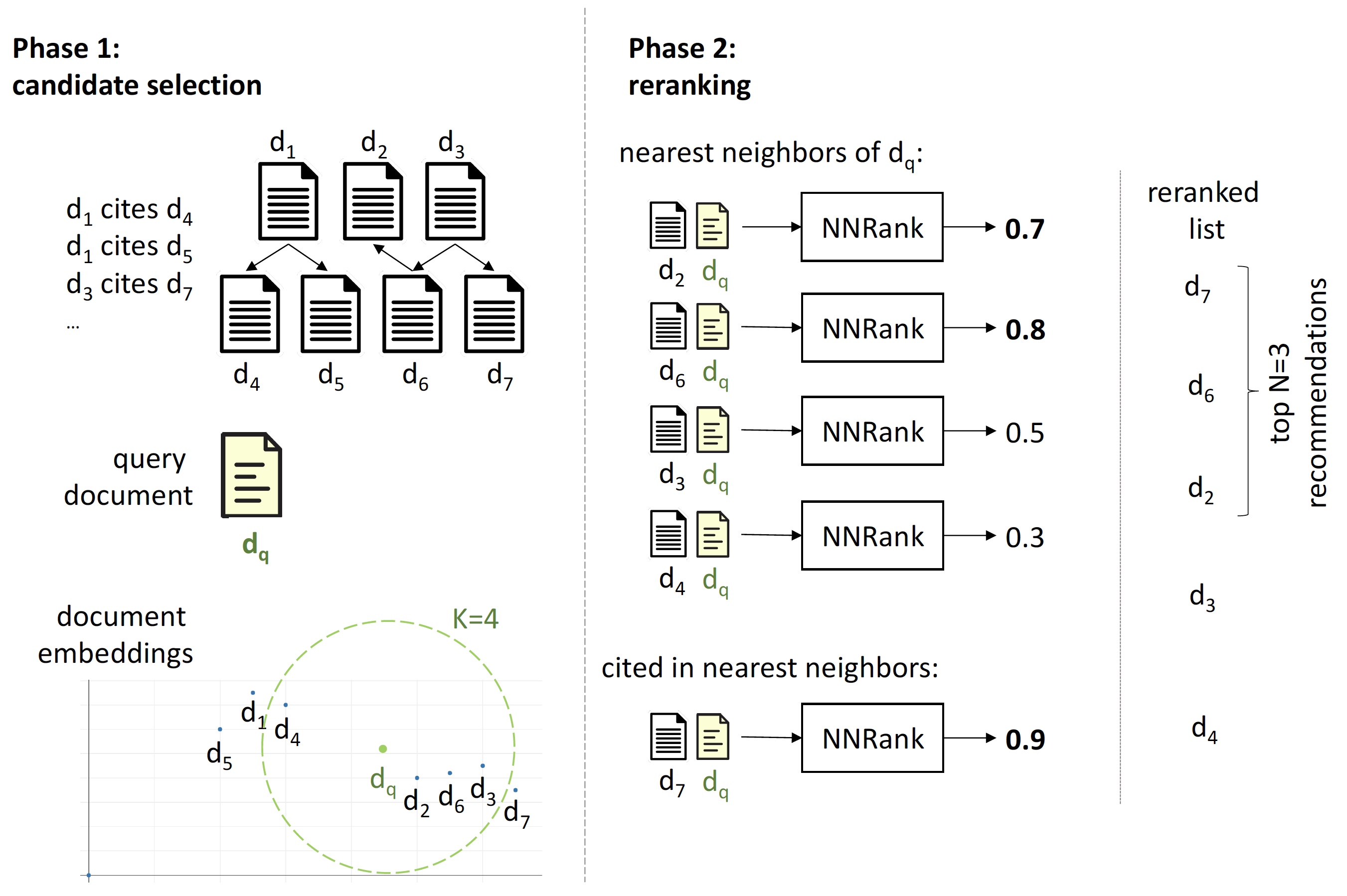
Phase 1 - Candidate Selection (NNSelect)
学習させた文書の埋込モデルを使って、クエリ論文に近い論文を推薦候補として取得する。
文書の埋め込みモデル
論文のタイトルとアブストラクトを用いて文書埋め込みを計算する。 タイトルとアブストラクトをそれぞれ Bag-of-Words 形式の表現にした後に重み付け和を取ったものを使用した。 これら重み付けタイトル・アブストラクト表現に対してそれぞれ学習可能なパラメータを用いた重み付け和を計算し、文書の埋め込み表現を取得する。
モデルの学習
クエリ論文 と引用されている論文 、引用されていない文書 の triplet を用いて学習を行う。
このとき は文書埋め込みのコサイン類似度 として定義される。
負例選択
- Random
- に引用されていない論文をランダムに選択
- Negative nearest neighbors
- 埋め込み空間上でに近いが引用されていない論文を選択
- Citation-of-citation
- には直接引用されていないが、が引用している論文に引用されている論文
Phase 2 - Reranking Candidates (NNRank)
推薦候補論文はクエリ論文に対して予測確率に基づいてソートされ、トップの論文が候補として提示する。
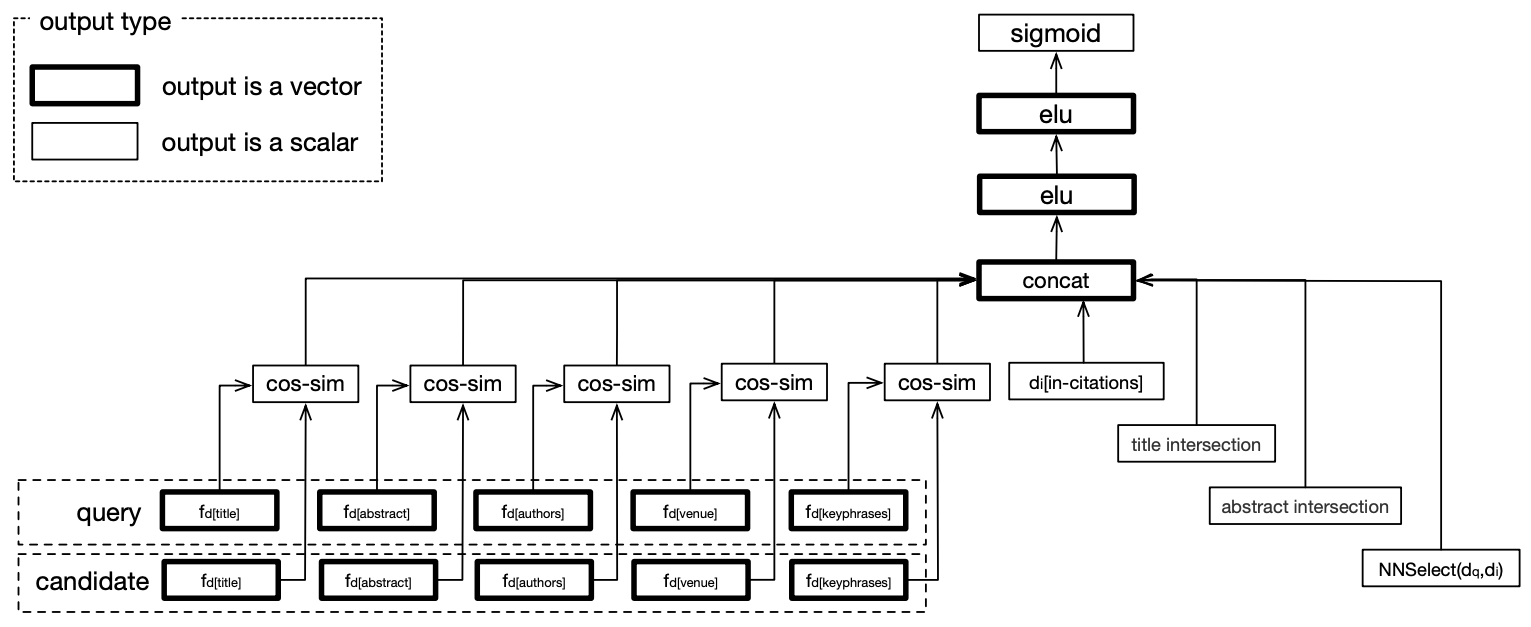
入力特徴
提案モデルでは論文のタイトルやアブストラクトのみで、メタデータを使用せずとも先行研究を超える性能を発揮するが、より性能を向上させるために以下の特徴を考慮した。
- タイトル
- アブストラクト
- 著者名
- 出版社名 (学会名)
- キーワード
- クエリ論文と候補論文とのテキストの交差特徴
- 論文被引用数
- テキストの埋め込み表現のコサイン類似度
モデルのアーキテクチャ
モデルの学習
入力特徴を concat したものをフィードフォワードニューラルネットワークに入力する。
損失関数としてNNSelectと同様にtriplet lossを使用する。
ここでは としてフィードフォワードニューラルネットワークの出力を sigmoid の通した値を使用する。
テスト時にはこの の値が一番高いものを推薦候補として使用する。
4. どうやって有効だと検証した?
論文引用推薦の評価に用いられる DBLP、PubMed データセットを使用した。
また新たに OpenCorpus という 700 万件程度のコンピュータサイエンスやニューロサイエンスの科学論文を集めたデータセットを構築し、モデルの評価に使用した。
ベースラインとして先行研究の Cluscite と BM25 に対して提案手法の比較を行った。
評価指標として Mean Reciprocal Rank (MRR) と F1@20 を使用した。
候補論文を NNSelect で探索するに当たり、近傍探索アルゴリズムとして Annoy を使用した。
また提案手法のハイパーパラメータを hyperopt で最適化した。
5. 議論はあるか?
負例選択について
モデルの学習時に埋め込み空間上でクエリ論文に近いが引用されていない論文を負例として使用することで、効率的に学習することが分かった。
有効な特徴について
各特徴量の貢献度合いを見ると、テキストの交差特徴が他の特徴量よりも予測に貢献していることが分かった。
出版社・学会名に対する頑健性について
出版社や学会のランクに対してロバストなモデルの構築が可能であることが分かった。
テキスト特徴のエンコーディングについて
CNN や RNN をテキストのエンコーディングに使用したが、それほど性能の向上には寄与しなかった。 本研究で使用している BoW ベースの文書埋め込みを使用することで計算量を小さくスケーラブルなモデルになる。
クエリ論文に対する近傍の数について
実験結果から 5-近傍のときに評価指標が最大となることがわかった。
自己引用のバイアスについて
メタデータ(例えば著者)で訓練されたモデルは、自己引用や他の有名な著者に偏っている可能性があると仮定し、
メタデータの有無でそれぞれ NNRank モデルを学習させる実験を行った。
メタデータを使って訓練されたモデルは、クエリ論文の著者の 1 人によって作成された論文を上位に推薦する傾向を確認した。