From Small-scale to Large-scale Text Classification
1. どんなもの?
カテゴリ数が非常に多いテキスト分類と比較的カテゴリ数の少ないテキスト分類を同時に行うマルチタスクなモデルアーキテクチャを提案。
2. 先行研究と比べてどこがすごいの?
テキスト分類においてカテゴリ数が非常に多い large-scale な問題設定と、比較的カテゴリ数の少ない small-scale な問題設定がある。
Web 検索のパーソナライズやレコメンドシステムなど、カテゴリ数が非常に多いテキスト分類は学習時に各カテゴリを捉えられるよう大規模なデータセットが必要である。
先行研究ではカテゴリ数の多いデータに対する研究はあるが、これらの手法は単語間の意味的類似性の重要度を考慮せずに、用語に対する重み付け手法のみを考慮している。 また、十分なデータ数が確保できない場合に対してマルチタスク学習を適用する研究はあるが、カテゴリ数の非常に多い大規模なテキスト分類に対する研究はとても少ない。
本研究ではカテゴリ数が非常に大きいものと比較的小さいもののテキスト分類のために、タスク間で有効な特徴を共有するマルチタスク学習と、 各タスクに有効な特徴を選択する gate 構造 を導入した convolutional neural network (CNN) ベースのネットワークを提案している。
3. 技術や手法の”キモ”はどこにある?
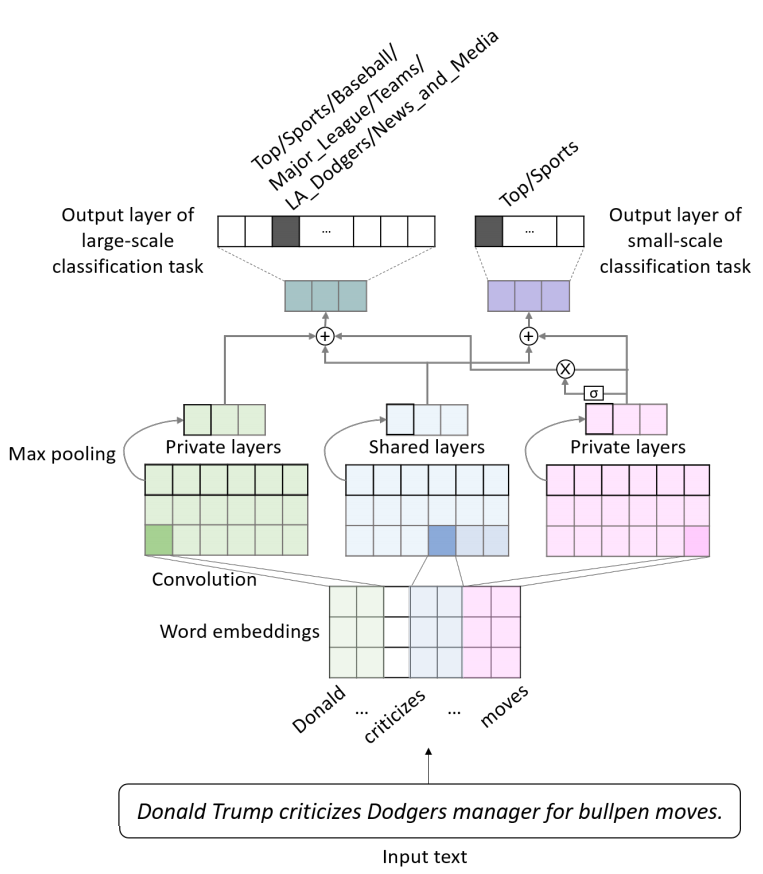
カテゴリ数の多い大規模なテキスト分類に対するマルチタスク学習
Shared layer と Private layer
- タスク間で不変な特徴とタスクで独立な特徴をそれぞれ捉えるモデルアーキテクチャ
- Shared Layer
- 各タスクに対して共有の畳込み+プーリングを用いて、タスク間で共通の特徴を学習可能
- Shared Layer
- Private Layer
- タスク固有の畳み込み+プーリングを用いて、タスク独立な特徴を学習可能
Gate 構造
小規模なテキスト分類タスクから大規模テキスト分類タスクへ効果的な特徴を選択する。
Large-scaleテキスト分類タスクにおいて、ゲート を用いて最終的な特徴量を得るSmall-scaleテキスト分類タスクにおいては以下となる
モデルの学習
Joint Traning
- ランダムにタスクを選択する (
large-scaleorsmall-scale) - 選択したタスクに沿った学習データを選択する
- これら学習データをもとに勾配降下法でパラメータを更新する
Oversampling
カテゴリ数の多いデータセットの場合、カテゴリごとで分布に差があるため、少ないカテゴリをオーバーサンプリングして対処する。
4. どうやって有効だと検証した?
データセット
- Open Directory Project (ODP)
- 大規模な木構造の web ページディレクトリ
- 15 階層に及び、前処理後には 3000 近くのカテゴリが含まれている。
- 大分類と小分類が含まれている。
Top/Sports,Top/Health,Top/ComputersTop/Sports/Baseball/Major_League/Teams/Los_Angles_Dogders/News_and_Media
- 学習データとして 23,000 ページを対象
-
Smal-scaleテキスト分類タスク用にトップレベルの 13 カテゴリを使用
- 大分類と小分類が含まれている。
- 大規模な木構造の web ページディレクトリ
- 15 階層に及び、前処理後には 3000 近くのカテゴリが含まれている。
- New York Times (NYT)
- ODP の追加テストデータとして、new york times の記事から
art,business,food,health,politics,sportsなカテゴリをランダムに取得して評価に使用した。
- ODP の追加テストデータとして、new york times の記事から
評価指標
- F1 score をベースに使用
- Micro-averaging (Mi-) F1 score
- テストデータ全体の F1 スコア
- データ数の多いカテゴリを正確に当てられているか
- テストデータ全体の F1 スコア
- Macro-averaging (Ma-) F1 score
- 各カテゴリ数に応じた F1 スコア - データ数の少ないカテゴリを正確に当てられているか
- Micro-averaging (Mi-) F1 score
- NYT データセットに対しては precision@k を使用
- 記事に対してアノテータが ODP のカテゴリとマッチするように
ベースラインモデルとの比較
- ベースモデル
- MC (Merge-Centroid)
- CNN
- LSTM
- BiLSTM
- 単語ベクトル系
- PV
- fastText
- マルチタスク系
- MT-DNN
- MT-CNN
- 提案手法
- SP-LSTM
- Share layer + Private layer w/o Gate
- SPG-CNN
- Share layer + Private layer w/ Gate
- SP-LSTM
5. 議論はあるか?
Gate 構造の比較
- 大規模分類タスクと小規模分類タスク間の gate 方向について
- large → small 方向より、small → large 方向のほうが良かった
異なる事前学習済み単語ベクトルを使用したときの精度比較
- word2vec や GloVe より fastText を用いたほうがよかった
- fastText は OOV に強い
ODP データセットに対する精度比較
Large-scaleテキスト分類タスクでは提案手法 SPG-CNN が outperformSmall-scaleテキスト分類タスクにおいては share layer + private layer のある LSTM が outperform- データが十分にあってカテゴリ間の分布が均衡なものは CNN より LSTM が強い傾向は先行研究でも確認されている
NYT データセットに対する精度比較
- 提案手法の SPG-CNN が outperform
- そのほかのマルチタスクモデルもシングルタスクモデルよりも良い結果
6. 次に読むべき論文はあるか?
- MC (Merge-Centroid) について