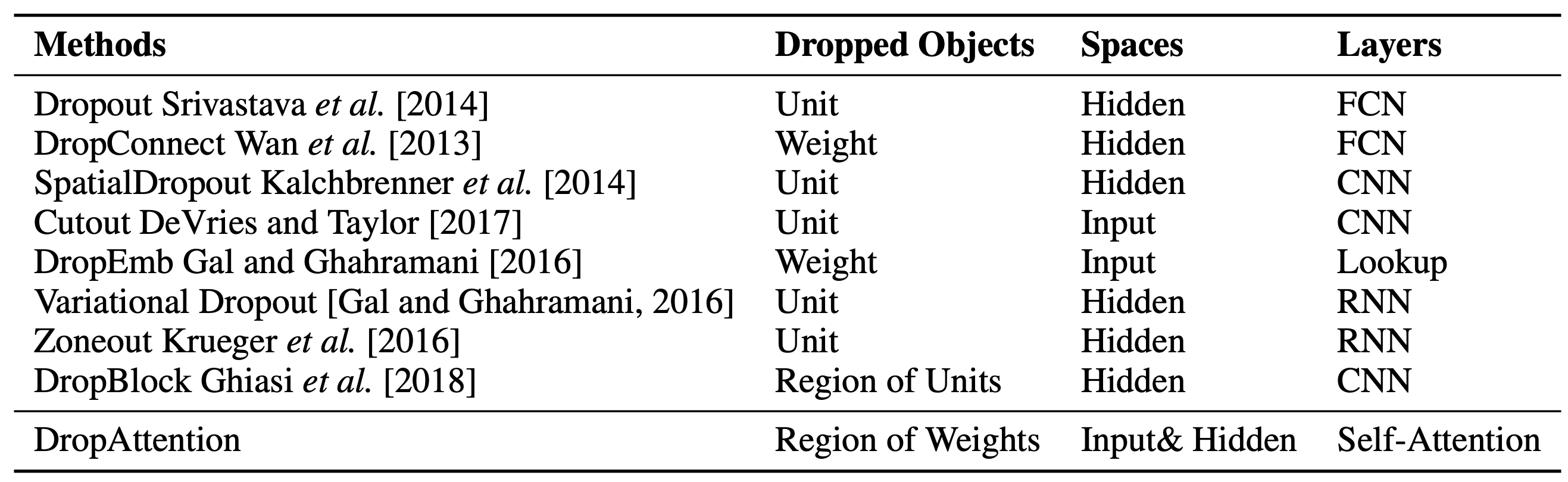
DropAttention: A Regularization Method for Fully Connected Self Attention-Networks
1. どんなもの?
全結合からなる self-attention 層に対して dropout を行う DropAttention を用いて過学習抑制し汎化性能向上を確認した。
2. 先行研究と比べてどこがすごいの?
Dropout は全結合層に対して確率的にノード落とすことで過学習を抑えることができる。 こうした手法は recurrent neural network (RNN) や convolutional neural network (CNN) にも応用されており、それぞれパフォーマンスの向上が確認されている。
本研究では dropout 手法を全結合からなる self-attention に対して適用する DropAttention を提案し、汎化性能向上を確認している。
3. 技術や手法の”キモ”はどこにある?
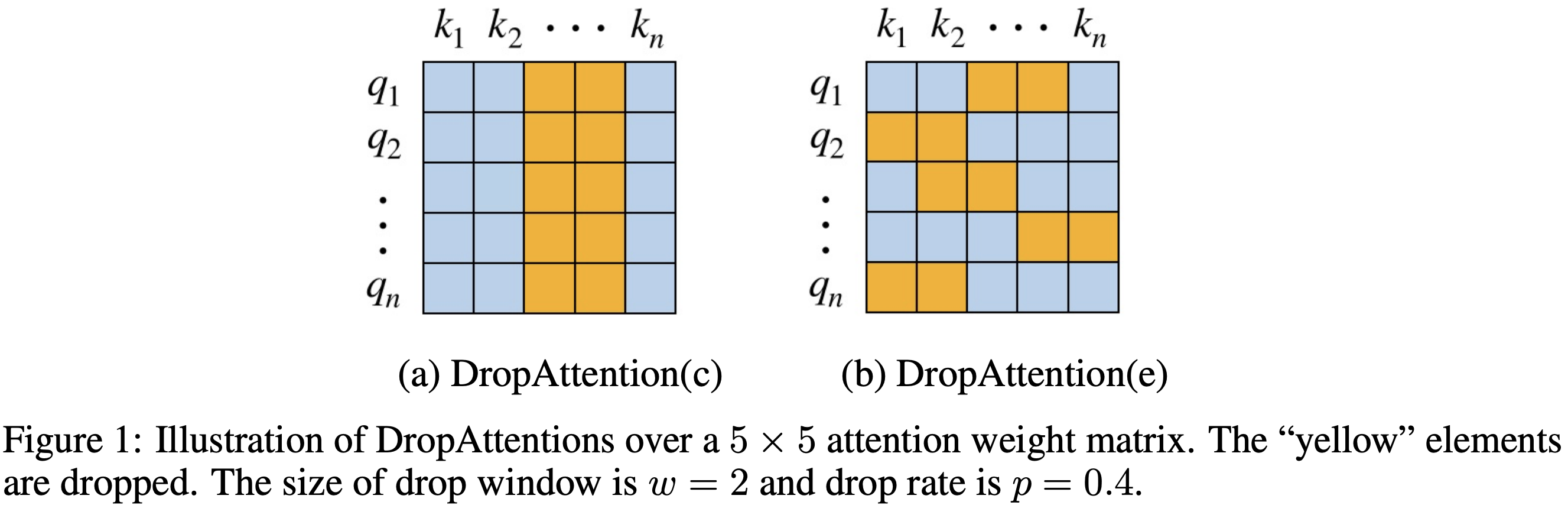
DropAttention
- 複数種類の dropout 手法を比較
- DropAttention(c)
- 列ベースで dropout する。先行研究の Dropout と同様の振る舞い。
- DropAttention(e)
- 要素ベースで dropout する。先行研究の DropConnect と同賞の振る舞い。
- これらの DropAttention にはハイパーパラメータとして dropout 率 と drop 対象となる連続した範囲を示すウィンドウサイズ の設定が必要である。
- DropAttention(c)
- Dropout 後のリスケーリング処理
- Attention に対して dropout した後に再度総和を取ると 1 となるようにリスケーリングを行う
4. どうやって有効だと検証した?
テキスト分類、系列ラベリング、テキスト含意認識、機械翻訳の 4 つのタスクに対して、DropAttention(c)および DropAttention(e)の効果確認を行っている。
5. 議論はあるか?
- DropAttention(c)および(e)のハイパーパラメータについて
- DropAttention(c)の場合 dropout 率は大きく、小さいウィンドウサイズを用いるのが良い
- DropAttention(e)の場合 dropout 率は小さく、大きいウィンドウサイズを用いるのが良い
- 先行研究である dropout も適用後にリスケーリング処理を行うが、同様の処理を DropAttention に適用すると性能が悪くなることが確認された。
6. 次に読むべき論文はあるか?
- Dropout 関連の論文がまとまっているので参考になる