Dynamic Routing Between Capsules
1. どんなもの?
Capsule構造とRouting-by-Agreementでアフィン変換に対してよりロバストになったCapsule Network(CapsNet)を提案.
2. 先行研究と比べてどこがすごいの?
Convolutional Neural Network(CNN)は画像認識において最先端のアプローチとなっているが,ある物体を他の視点からみたサンプルに対する予測精度は低い.これは予めアフィン変換を施した学習データを用いることで対処されるが,特徴量の学習は次元数の増加に応じて指数関数的に増加してしまい,効率が悪い.
先行研究で提案されているCapsuleは,ニューラルネットワークのある層がサブ構造を含むようなアーキテクチャを利用することで指数関数的な効率の悪さを抑えたものとなっている.
また先行研究で用いられているCNNは以下のような欠点が存在している.
- CNNはある一方向のみの物体で学習を行っている場合,回転を扱うことができないため,向きが変わると予測できない場合がある.
- プーリング操作を行うととても深いレイヤーでは位置に対する不変性が得られるが,とても荒い表現になってしまう.
- 例えば鼻や口などの正確な空間関係を損なってしまう.顔認識の場合は鼻や口といった物体の正しい空間関係の認識が必要である.
本研究では計算効率の良いCapsule構造を取り入れ,非線形変換である「squash」,およびプーリング操作に変わりアフィン変換にロバストな「routing」からなるCapsule Networkを提案している.
3. 技術や手法の”キモ”はどこにある?
- Squash
- 通常の典型的なニューラルネットワークでは、ユニットの出力のみがReLUといった非線形活性化関数によって潰される.
-
Capsule Networkでは,Capsuleから出力されるベクトル全体が潰される.
- Routing (Routing-by-Agreement)
- 特徴の関連性に基づいて次のレイヤーのCapsuleにルーティングする.
- Max-poolingでは最大の値のみ保持するが,これがCNNの欠点とも言える.
- RoutingによってCapsuleは前の層からの特徴の加重和を得る.これは物体が重なっている場合の特徴検出に適している.

- CapsNet
- 全体のアーキテクチャ
Convolution+ReLU > PrimaryCapsules > DigitCaps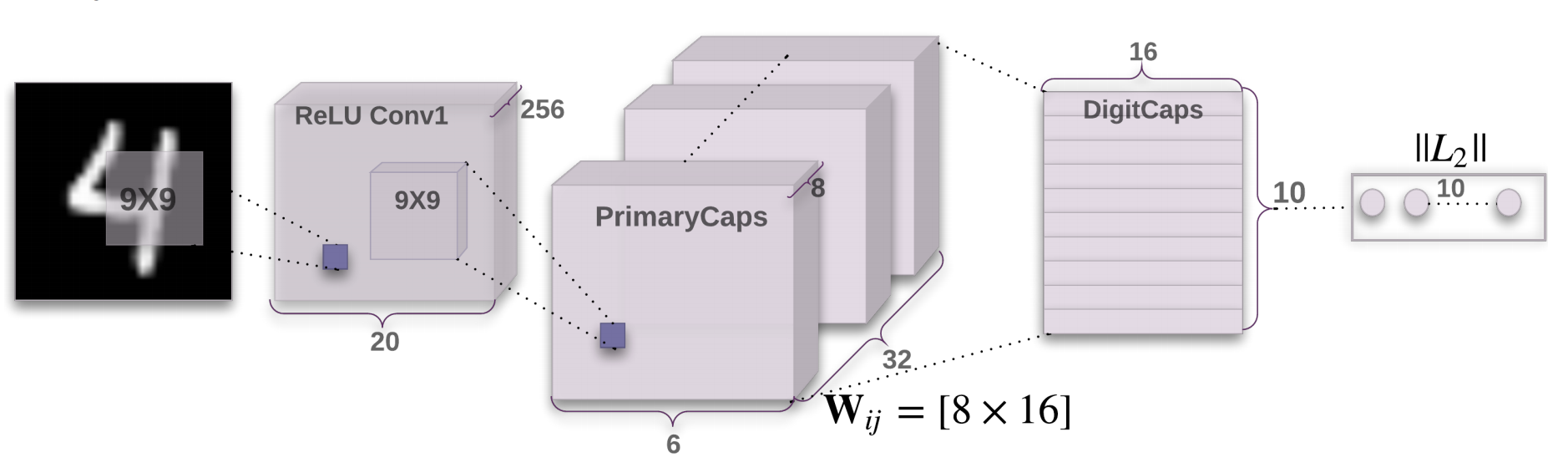
- PrimaryCapsules
- 32チャンネルのConvolutional 8D Capsules
- 各primary capsuleは9x9のカーネルでstrideが2のconvolutionユニットが8つから構成されている.
- PrimaryCapsulesは複数のConvolutionの結果をsquashしていると見ることができる.
- 32チャンネルのConvolutional 8D Capsules
- DigitCaps
- 1クラスあたり16のDigitCapsの構造であり,各クラスについてよりロバストな表現を学習する.
- Margin loss
-
複数のクラスを許容するために,各クラスに対応するCapsuleに対してmargin lossを定義している.
-
各クラスに対するlossをすべて足し合わせて全lossとする.
-
- 全体のアーキテクチャ
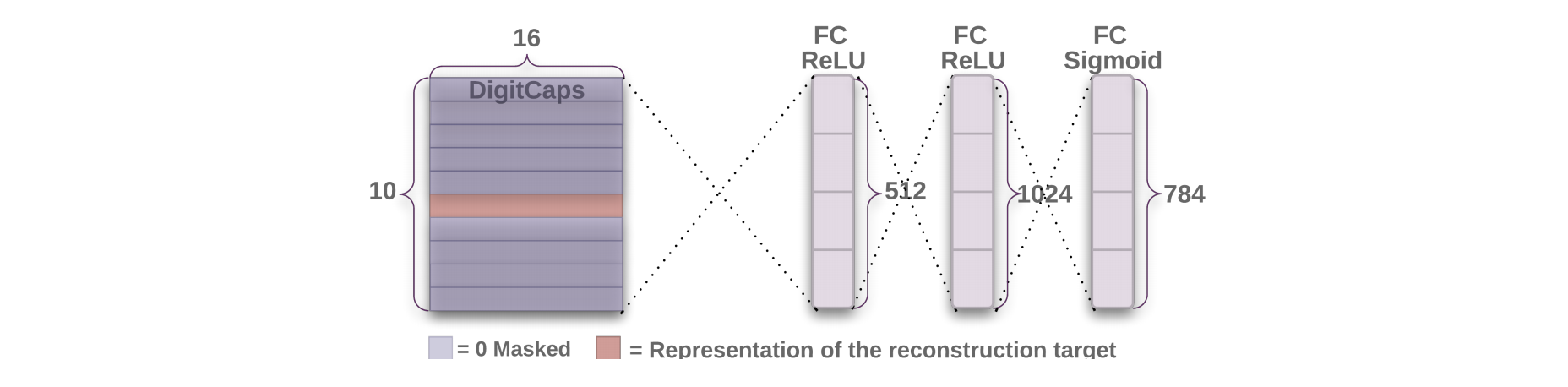
- 再構成による正規化効果
- margin lossの他に入力画像と再構成画像とのMSEをreconstruction lossとして追加している.
- DigitCapsの後段に3層の全結合層を持つDecoderを導入し,正則化の効果を追加している.
- 学習時には再構成対象の特徴表現のみを利用し,それ以外はマスクしている.
4. どうやって有効だと検証した?
-
MNISTデータセットを用いた精度比較
ベースラインとなる先行研究の3層のCNNとCapsNetの精度を比較している.ベースラインモデルのパラメータ数が35.4Mに対して,CapsNetは8.2Mであり,再構成に使われているパラメータ数を除くと6.8Mであることから,ベースラインのモデルより少ないパラメータ数でよりよい精度を出していることがわかる. -
アフィン変換に対するロバスト性
予めMNISTデータセットで学習したベースライン/CapsNetの両モデルに対して,MNISTデータセットにアフィン変換を施したaffNISTデータセットをテストデータとして用いて精度を比較している.ベースライン/CapsNetの両モデルともにトレーニングデータに対しては99%以上の正解率を出しているが,テストデータにおけるベースラインの正解率は66%であった.これに対しCapsNetは正解率79%と先行研究と比べてとても高い精度を出している. -
重なり合っている物体の認識について
異なるクラスに属する数字が重なり合っているようなデータセットであるMultiMNISTデータセットを作成し,Routingが一種のAttentionのような働きをしていることを確認する実験を行っている.これは複数のオブジェクトが重なり合っていても認識できる効果があると考えられている.
以下の再構成画像ではCapsNetが重なり合う2つの数字をそれぞれ正確に認識していることがわかる.

5. 議論はあるか?
- Capsuleに関する研究は今世紀初めの音声認識のためのRecurrent Neural Networkの研究と同様の段階にある.
- Capsuleがより良いアプローチだと信じる根本的な理由はあるが、CNNのような近年爆発的に研究されてきた技術を凌駕するには,もっと小さな洞察を必要だろう.
- シンプルなCapsule構造がすでに重なり合う数字を分けて認識し,とてもよい性能を発揮しているという事実は,Capsule構造が今後研究対象として価値のあるものと考えているので,早期に結果を示してみた.
6. 次に読むべき論文はあるか?
- Capsuleについて
- MNIST/affNISTデータセットの精度比較におけるベースラインのモデルについて
- MultiMNISTデータセットの精度比較におけるベースラインのモデルについて