Unsupervised Deep Embedding for Clustering Analysis
1. どんなもの?
特徴表現の学習とクラスタリングを同時に行う,Deep Embedding Clustering(DEC)を提案.
2. 先行研究と比べてどこがすごいの?
一般的なクラスタリング手法としてk-meansやGaussian Mixture Model(GMM)などがあげられる.これらの手法は幅広いアプリケーションに適用されている. しかしながら入力の次元数が大きい場合には計算量が増大してしまい,効率が悪くなってしまう.
k-meansを改良して高次元の入力に対しても効率よく扱う手法も提案されているが,線形の埋め込み表現に限られてしまっている.
柔軟な距離計算が導入できるスペクトラルクラスタリングでは,k-meansよりよいパフォーマンスを発揮することが知られているが, メモリの消費量が大きかったり,データ数が大きくなると計算が難しくなるといった問題がある.
本研究では,高次元で規模の大きいデータセットに対しても効率的にクラスタリングできるよう特徴量を学習する Deep Embedding Clustering(DEC)を提案している.
3. 技術や手法の”キモ”はどこにある?
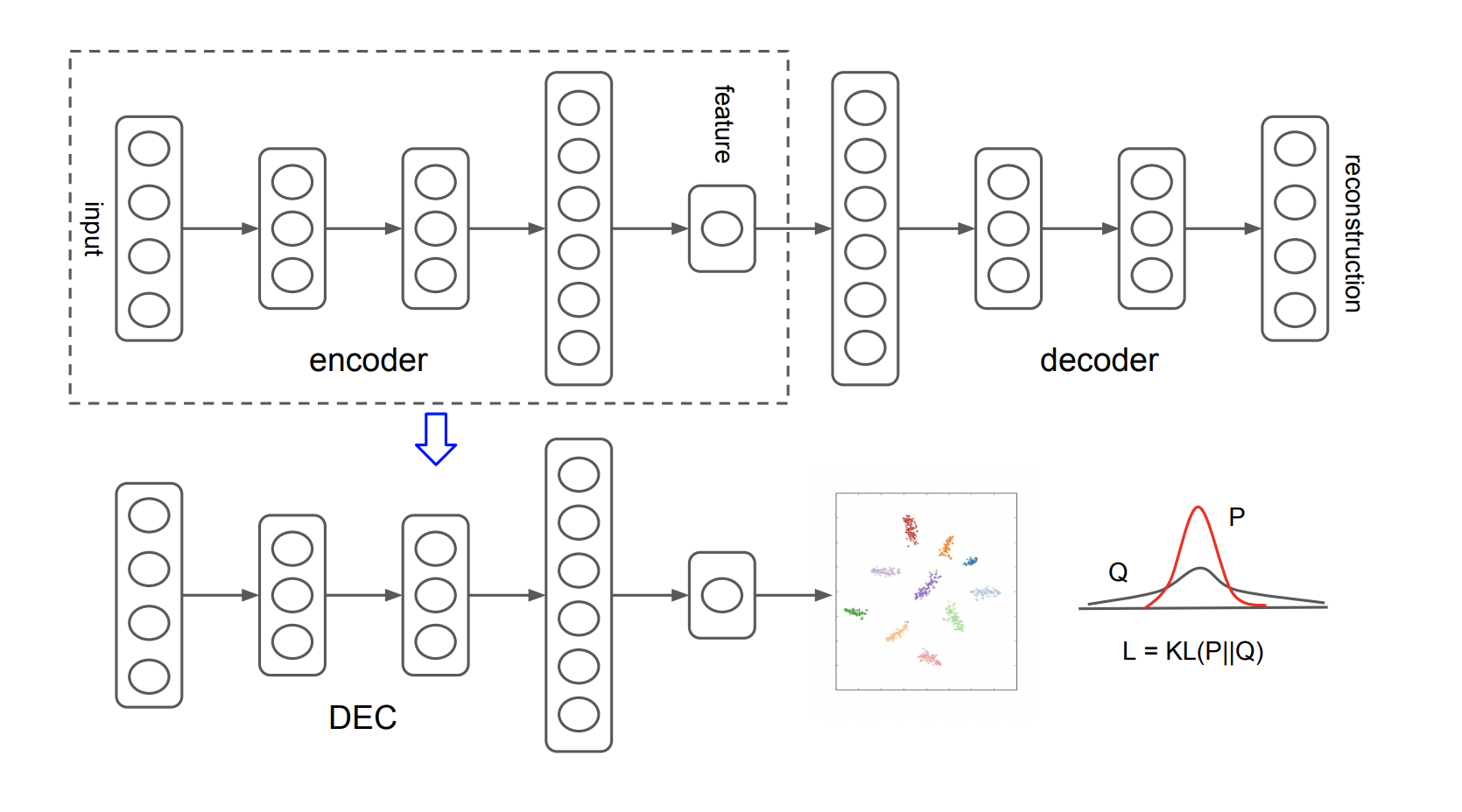
- Deep Embedding Clustering
- KLダイバージェンスを用いたクラスタリング
- 埋め込み先データ点とセントロイドとの距離はt分布で計算する
- Auxiliary target distribution(今回はデルタ分布)とのKLダイバージェンスが小さくなるように計算を行う
- 提案モデルの学習過程はself-trainingと捉えることができる
- Deep Neural Network(DNN)のパラメータ初期化
- 提案モデルはStacked autoencoder(SAE)を用いて初期化
- 各autoencoderはdenoising autoencoderとして,ノイズの乗った入力に対してノイズを除去するような出力を得るよう学習させる
- KLダイバージェンスを用いたクラスタリング
4. どうやって有効だと検証した?
MNIST,STL-10,REUTERSの3つのデータセットを用いてる,教師なし学習の評価指標であるunsupervised clusering accuracy(ACC)を評価指標とし,先行研究のk-means,LDMGI,SEC,DECとbackpropなしのDECを比較している.
5. 議論はあるか?
- 非線形写像であるDNNをfreezeした場合(DEC w/o backprop)は通常のDECよりもパフォーマンス面で悪くなっている.
- 信頼度が高いものについては大方正しいクラスタに属している.信頼度が低いデータは曖昧なもので,最終的には違うクラスタと判定してしまう場合もある.
- SGDのような反復的な最適化を行うことで,学習が進むに連れ綺麗にクラスタに別れていることがわかる.
- DNNのパラメータをautoencoderで初期化しなかった場合のパフォーマンスは低かった.
- 不均衡なデータに対しても提案手法であるDECはよいパフォーマンスを見せている.
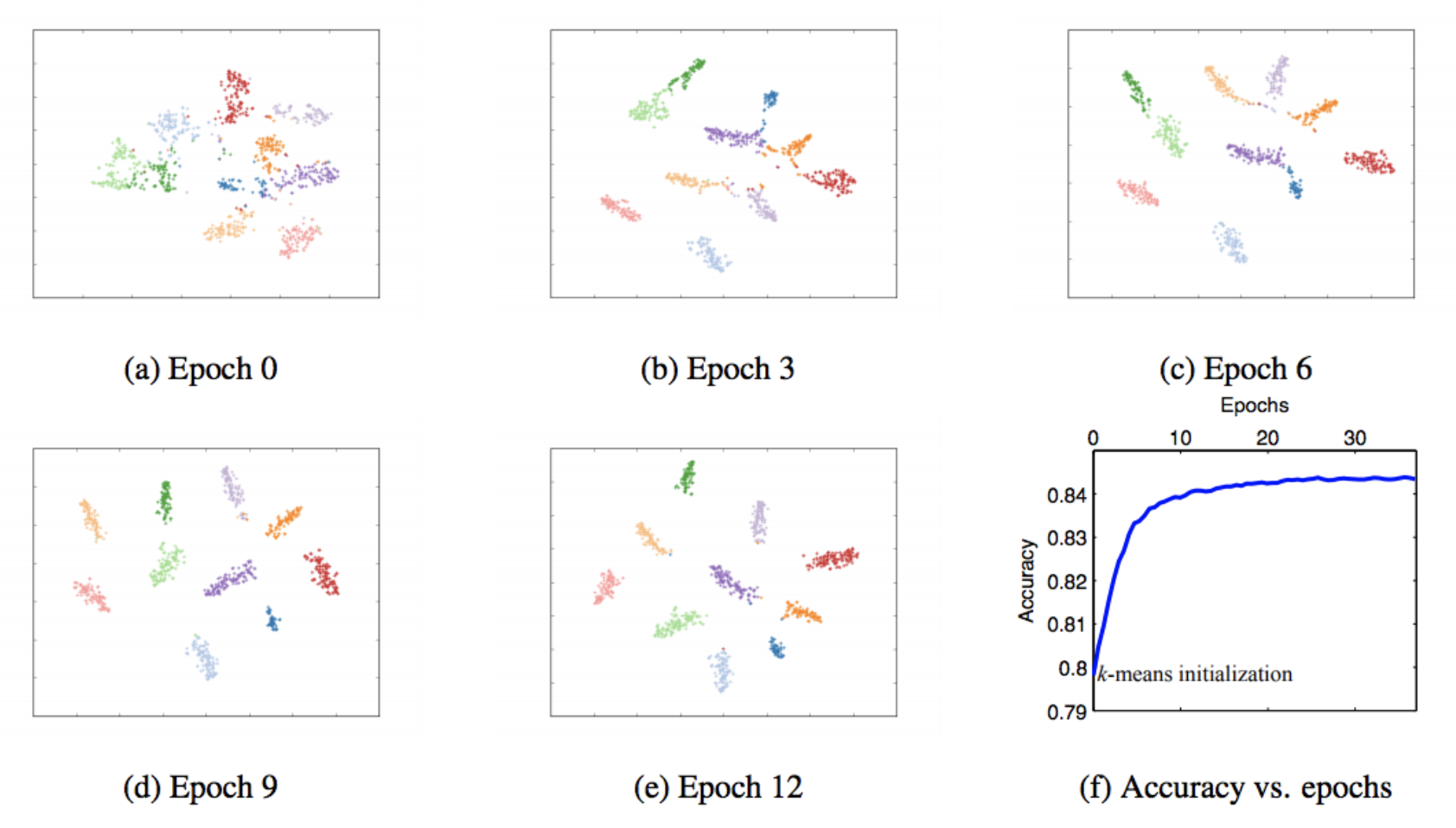
6. 次に読むべき論文はあるか?
self-trainingについて
LDMGIについて
SECについて