Character-level Intra Attention Network for Natural Language Inference
1. どんなもの?
自然言語推論に対して文字レベルの特徴とIntra Attentionを用いたCharacter-level Intra Attention Network(CIAN)を提案している.
2. 先行研究と比べてどこがすごいの?
自然言語推論(Natural Language Inference(NLI))は,自然言語処理タスクの一つである.「前提(premise)」と「仮説(hypothesis)」からなる2つのテキストを用いて学習を行い,前提と仮設が正しいか・矛盾しているか・中立かを予測する. 先行研究ではNLIタスクに対してRNNベースのエンコーダを利用したものが多く,特にLSTMやGRUなどが幅広く使われている. これらのエンコーダーは単語レベルのembeddingを用いており,Word2VecやGloveなどの学習済み単語ベクトルで初期化することが多い.
しかしながら近年のコーパスにおける語彙数の増加により,予め用意した単語ベクトルには含まれない,語彙外の単語が多く存在してしまう.
本研究ではベースラインモデルのEmbedding層の代わりに,文字レベルの特徴を用いるConvolutional Neural Network(CharCNN)を適用している.またIntra attentionを適用することで,よりリッチな文構造を学習することが可能となっている.
3. 技術や手法の”キモ”はどこにある?
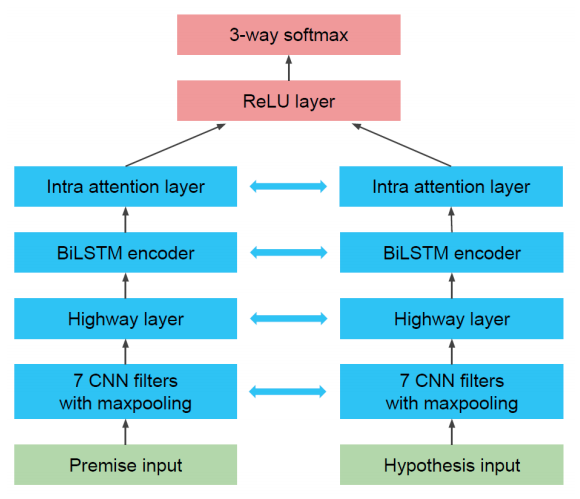
- Character-level Intra Attention Network
- Character-level Convolutional Neural Networks
- 文字レベルの特徴を用いることで単語レベルの特徴を用いるときに発生してしまう語彙外の単語の出現を抑えることができる
- 畳み込み層は「GermanやGermany」といったつづりの違いについても特徴を抽出することができる
- Intra Attention
- 先行研究で文書分類に対して導入されたIntra AttentionをNLIタスクに適用
- BiLSTMの隠れ状態と重み・バイアスを活性化関数tanhへ通すことで隠れ表現を得たのち,softmaxを掛けることで重要度を表す重み行列を得ることができる
- Character-level Convolutional Neural Networks
4. どうやって有効だと検証した?
NLIタスクを評価する際に使用されてきたStanford Natural Language Inference(SNLI)コーパスと,新たに導入された大規模なコーパスであるMulti-Genre NLI(MNLI)コーパスを使用している. 提案モデルの学習の際にはMNLIのトレーニングデータすべてを利用したのと,SNLIトレーニングデータセットから20%程度ランダムに選んだデータを使っている.
ベースラインのBiLSTMを用いたモデルと比較すると,提案モデルがよりよい精度を出していることがわかる.
5. 議論はあるか?
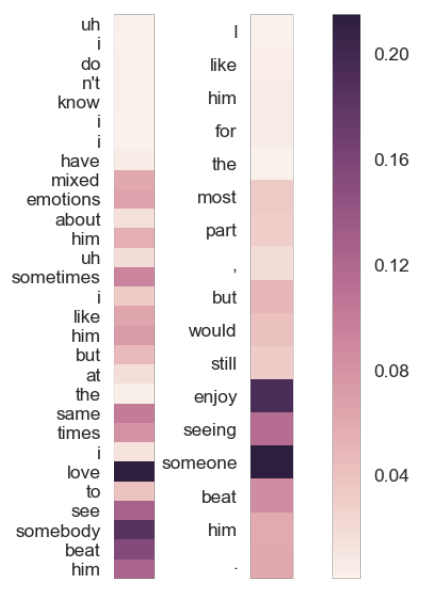
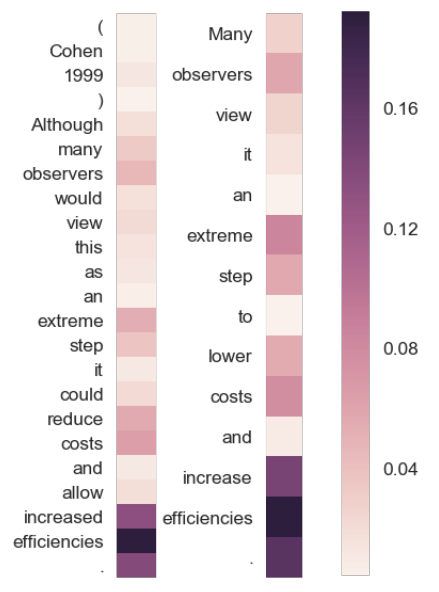
Attentionの重みを可視化した結果は以下のようになっている.左が前提の文で右が仮説の文を表している.より色が濃い単語が重要で予測に寄与しているものとなっている. 可視化の結果から,モデルはより似ている意味を持つ単語(ここではloveやenjoy)に注意をしていることがわかる.
6. 次に読むべき論文はあるか?
CharCNNについて
Intra attentionについて