Visualizing and Understanding Convolutional Networks
1. どんなもの?
学習済みのConvolutional Neural Networks(CNN)における中間層の機能とモデルの動作を洞察することができる可視化手法を提案.
2. 先行研究と比べてどこがすごいの?
CNNは画像認識の分野で素晴らしい成果を上げているが,なぜそのようなパフォーマンスが発揮されているか,またどのような過程を経て予測を行っているのかが明らかになっていない.
先行研究ではCNNではないDeepなNeural Networkについて可視化を行っているものや,ネットワークのパラメータに対してヘッセ行列を計算し,どのような振る舞いをしているのか考察を行っているものがある. これらは上位の層で学習されたとても複雑な不変量に対してのみ行われているものであり,単純な2次近似から特徴を考察しているものである.
本研究ではノンパラメトリックな不変量への考察と,学習データに対する特徴マップの活性化度合いを可視化することで,CNNモデルを理解しようとするものである.
3. 技術や手法の”キモ”はどこにある?
Deconvnetを用いた可視化
CNNの動きを理解するためには中間層の働きを解釈する必要があるが,この中間層の働きを可視化するためにdeconvnetを利用する. CNNの各層に対応するようdecnovnetを構築する. CNNで得た特徴マップをDeconvolutionやUmpooling,Rectificationを繰り返して入力の画像空間へ再構築する.
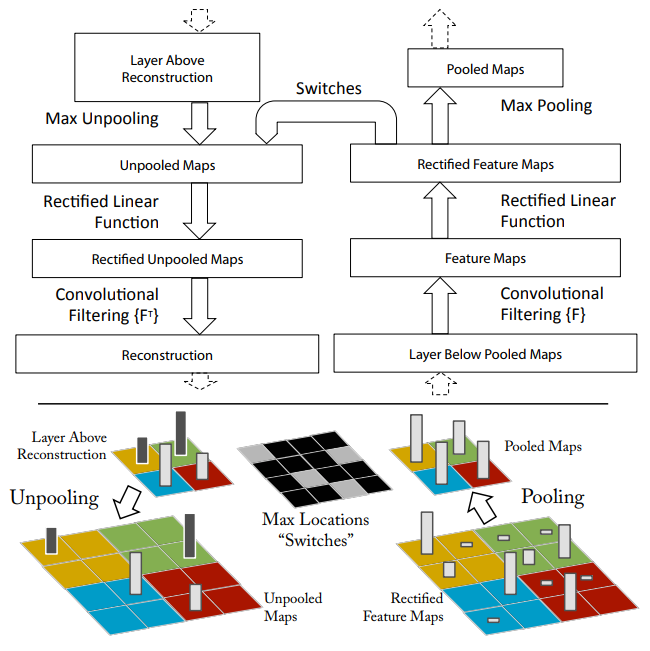
Unpooling
Maxpoolingの逆操作をUnpoolingで行う.deconvnetでは,CNNでpoolingされた位置と値を保持しておくことでunpooling操作を可能にしている.
Rectification
特徴マップの再構成に有効なシグナルを得られるよう,unpoolingされた値に対してReLUを適用する.
Filtering
convolutionは学習されたフィルタを使用して,前の層の特徴マップを畳み込む.この逆操作を行うため,deconvnetでは同じフィルタを転置したものを利用する.なおReLUに通した後にdeconvolutionを適用する.
CNNの可視化
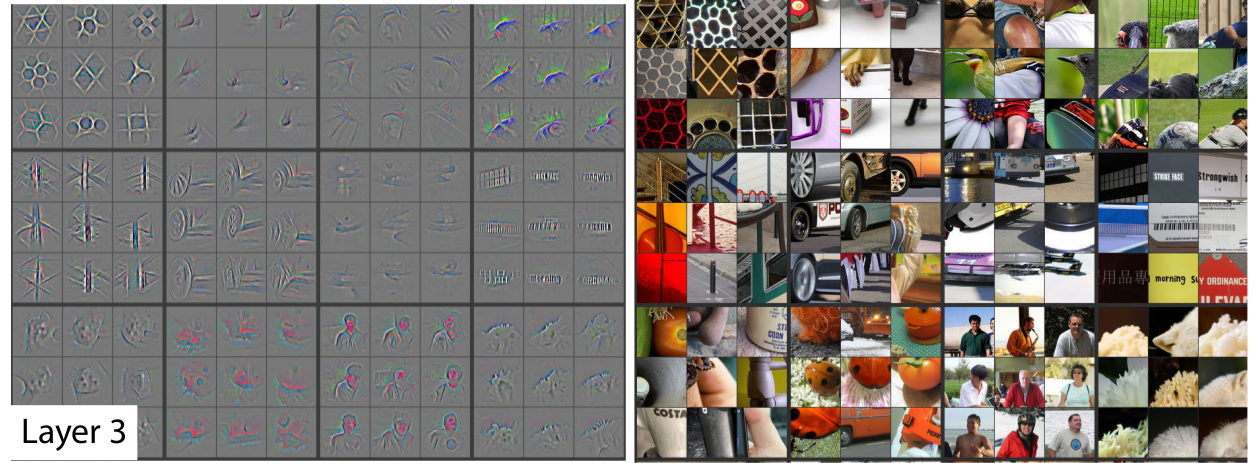
学習した特徴の可視化
学習済みのモデルの可視化を行った.
各層の特徴マップのうち,特に活性化の度合いが強いもの9つを選択して再構築したものと,それに対応する原画像を並べている.
各層ごとに階層的に特徴を学習していることが分かる.
- 第2層目:コーナーやエッジ,色の交差
- 第3層目:メッシュパターンやテキストパターンといったより複雑な模様
- 第4層目:第3層よりもバリエーションが豊富な模様で,より詳細にカテゴリの特徴を表している
- 第5層目:全体のオブジェクトが現れている.キーボードや犬など


学習時に学習される特徴の変化
全学習データを学習している際に,学習が行われて変化していく特徴マップの過底を示している.
モデルの浅い層では数epochで収束するのに対し,深い層では40-50epochをかけて収束していくのが分かる.

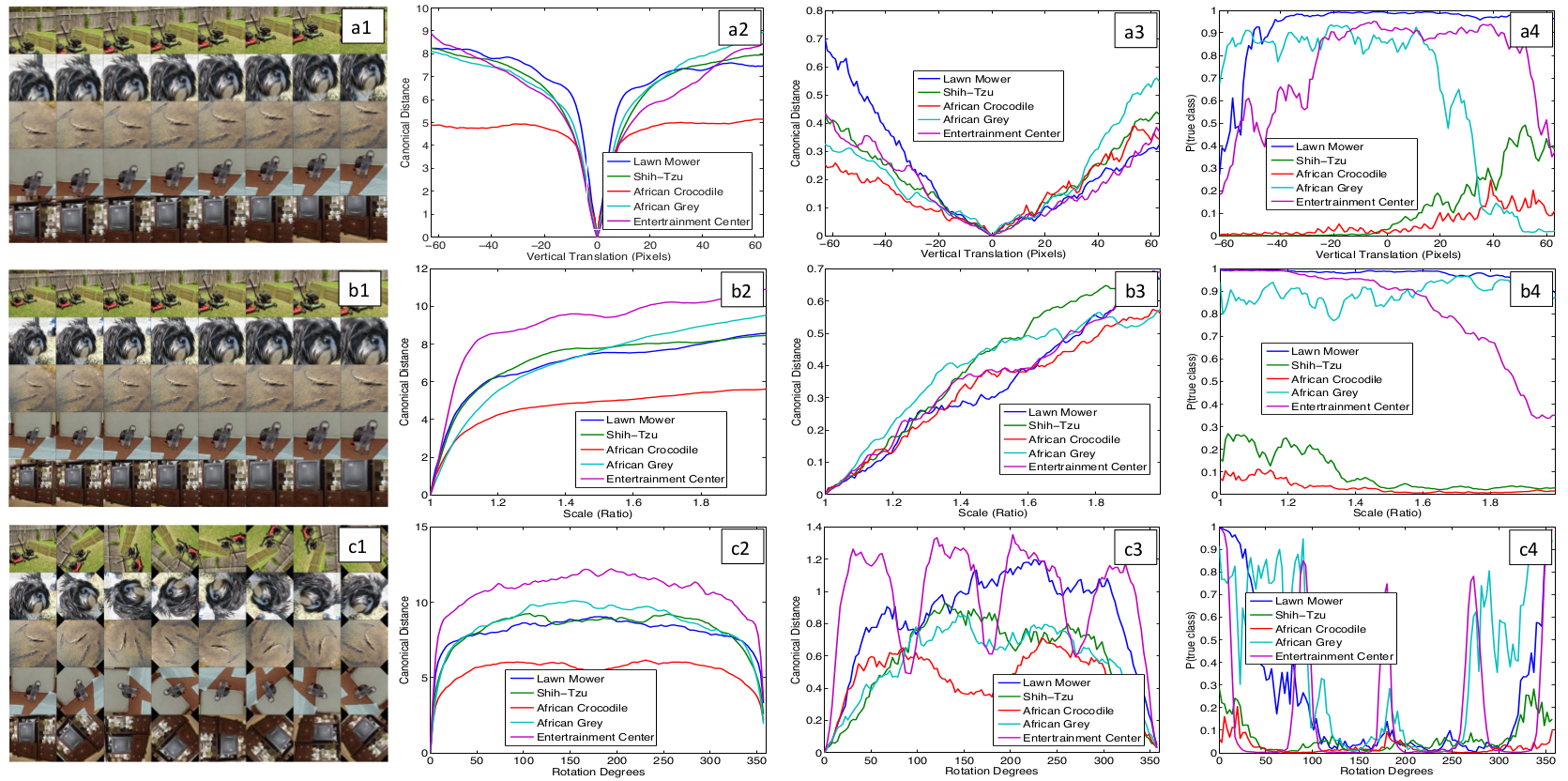
特徴の不変性
5つのサンプル画像に対して,変形操作を行っていないものと回転や平行移動,拡大縮小の操作を行った画像をモデルに入力した際の挙動を図示している.
小さな変形はモデルの第1層で劇的な効果を持つが,深い層での影響は小さい.変形やスケーリングに対してモデルの出力は安定している.
モデルアーキテクチャの選択
モデルの可視化によってモデルの動作を理解することができた.
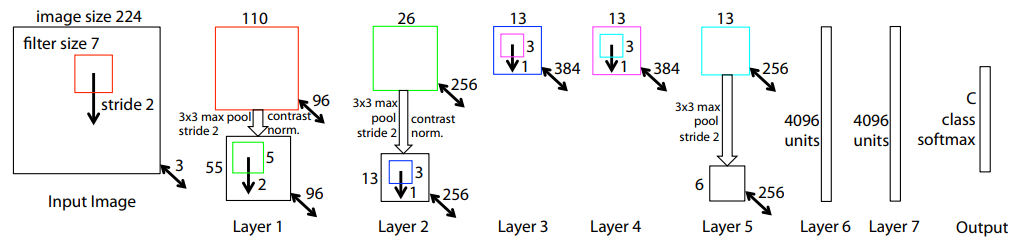
AlexNetの第1層および第2層を可視化することで,いくつか問題が見つかった.
- 第1層目:高頻度および低頻度の情報のみしか学習しておらず,中程度で現れるような特徴に対しては学習しきれていない.
- 第2層目:ギザギザとしたノイズが乗ってしまう「エイリアシング」が発生していることがわかる.これは第1層目のConvolutionのstrideが4と大きいためだと考えられる.
解決策として以下の2つが挙げられる.
- 第1層目のフィルタサイズを11x11から7x7に変更する
- 第2層目のConvolutionのstrideを4から2に変更する
結果的にモデルの予測精度が向上している.

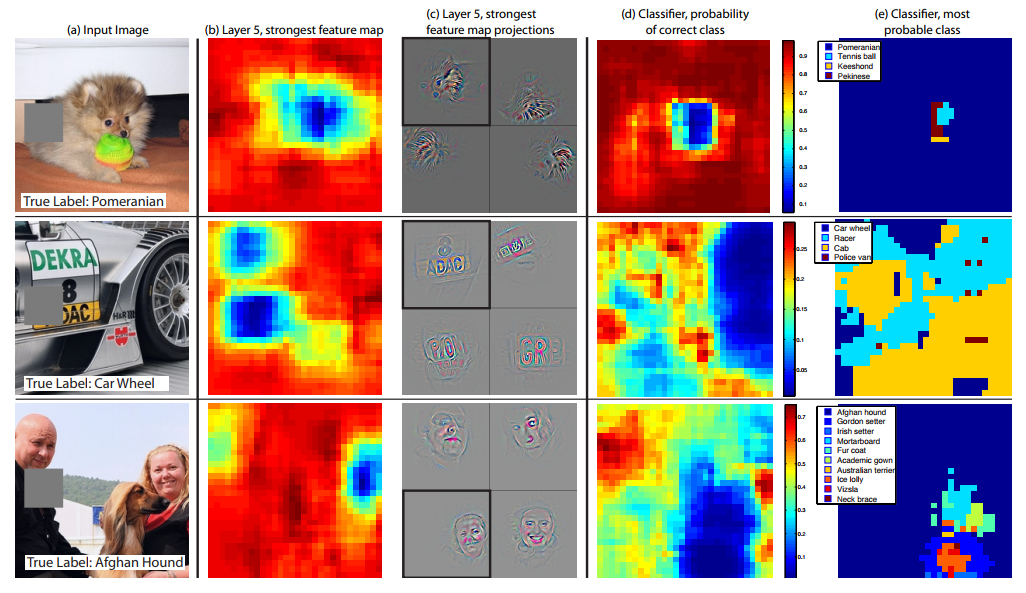
対象をマスクした場合の挙動
モデルが画像を分類する際,対象オブジェクトの位置は有効であるか,それとも周辺の情報が有効であるか実験を行った.
入力画像の一部をグレーで塗りつぶした矩形で隠した後,分類を行った結果を考察している.
対象オブジェクトを隠した場合に予測精度は大幅に減少した. また特徴マップの活性化度合いも大幅に低下していることが確認できた.
対応分析
深い層のモデルは,明示的に顔にある目や鼻といったオブジェクト間の対応を明示的に学習していない.しかしながら,浅い層のモデルでは暗黙的にそういった対応関係を学習している可能性がある. この仮定を調べるため,5つの犬の画像のサンプルに対して,すべて左目だけ隠す,といったように体系的にマスクを施してモデルの挙動を確認した.
目と鼻を隠した場合にスコアが低くなったが,これはモデルが暗黙的に顔のパーツの対応を確立していると言える.

4. どうやって有効だと検証した?
ImageNetデータセットに対して,本研究の可視化手法で分かったAlexNetの欠点を改善した上図Figure 3のモデルを適用したところSoTAな結果を出すことができている.
またImageNetで学習したモデルが一般性のある特徴を学習しているかを確認するため,Caltech-101,Caltech-256,およびPASCAL VOC2012を用いて精度を確認している. この時一番最終のsoftmax層部分のみを再学習させている.
5. 議論はあるか?
- PASCALデータに対しては複数物体を捉えられるような損失関数に変更することでより良い精度が出せるのではないだろうか
- 上記が達成できれば物体認識にモデルを適用することができそう
6. 次に読むべき論文はあるか?
Deconvnetについて
- Zeiler, Matthew D., Graham W. Taylor, and Rob Fergus. “Adaptive deconvolutional networks for mid and high level feature learning.” Computer Vision (ICCV), 2011 IEEE International Conference on. IEEE, 2011. CNNではないDeepなNeural Networkについて可視化を試みたもの
- Erhan, Dumitru, et al. “Visualizing higher-layer features of a deep network.” University of Montreal 1341 (2009): 3.