Deconvolutional Paragraph Representation Learning
1. どんなもの?
ConvolutionおよびDeconvolutionを用いて,長い文章の潜在的表現を計算効率よく学習する枠組みを提案している.
2. 先行研究と比べてどこがすごいの?
文章の特徴を学習するようなタスクに対しては,これまで時系列情報を扱えるRecurrent Neural Networks(RNN)ベースのencoder-decoderが提案されてきた. しかしながらRNNベースのモデルを用いた文章のデコード(再構成)では文章の長さが長くなるほど性能が落ちてしまうことが確認されている.
本研究ではRNNを用いず,Convolutional Neural Network(CNN)をencoder,Deconvolutional Neural Network(DCNN)をdecoderに用いたencoder-decoderモデルで文章の特徴を学習させている.
加えてCNNはRNNと比べて高い並列処理性を有するため,より計算効率よく学習させることができる.
3. 技術や手法の”キモ”はどこにある?
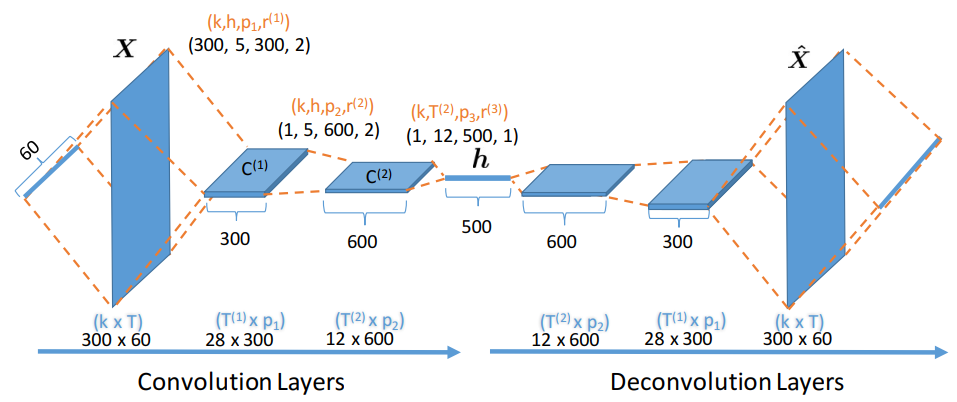
- Convolutional encoder
- 浅い層のフィルタはn-gram情報(画像における「エッジ」情報に類似)を学習し,深い層のフィルタはセマンティックな構文構造(画像における個々のオブジェクト情報)を学習している.
- max-poolingといったpooling処理を用いずstrideを調整した畳み込みを用いている.これは畳み込み操作だけで空間的ダウンサンプリングを学習できるからだと考えられている.
- 本研究の初期実験ではmax-poolingを入れたモデルで精度があまり出なかった.
- Deconvolutional decoder
- Convolutionの転置操作を行う.
- RNNと比べて長い文における共起を捉えるのに優れているため,分類問題や文書要約のための特徴抽出に効果がある.
- 本研究のConvolutional autoencodingを半教師ありの分類と要約タスクを解けるよう拡張
- 半教師ありタスクをマルチタスク学習として捉え,エンコーダーと教師ありモデルを同時に学習させる.
- 学習させた潜在的表現は高い再構成性や分類能力を保持する.
-
以下のLoss関数を定義して半教師あり学習の枠組みを導入.
- ラベル付きデータとラベル無しデータを用いてautoencoderのlossとclassifierのlossを最小化するよう学習.
- ハイパーパラメータαを導入して学習初期は文の概要を捉えるよう焦点を当て,学習が進むにつれて細部を学習するようにする.
- 半教師ありタスクをマルチタスク学習として捉え,エンコーダーと教師ありモデルを同時に学習させる.
4. どうやって有効だと検証した?

- encoder-decoderの構造それぞれCNN-DCNN,CNN-LSTM,LSTM-LSTMとして各タスクで評価を行っている.
- 文章の再構成タスクでは,Hotel Reviews Datasetを用いてモデルを学習させ,ROUGEおよびBLEUスコアの比較を行っている.
- 文字レベル・単語レベルの訂正タスクでは,Yahoo! Answer datasetを用いてモデルを学習させ,Character Error Rate(CER)およびWord Error Rate(WER)の比較を行っている.
- 半教師ありの文書分類および要約タスクでは,DB Pedia,Yahoo! Answers,そしてYelp Review Polarityの各データセットを用いて評価を行っている.
5. 議論はあるか?
- 言語生成タスクにおいては.RNN decoderは通常Deconvolution decoderと比較してより辻褄の合った文章を生成する.
- RNN decoderから単語列を生成するためには,文全体から再帰的に学習された隠れベクトルが必要である.
- Deconvolution decoderは予め指定されている単語列の構造をカプセル化するような表現を学習している.