Contextual Augmentation: Data Augmentation by Words with Paradigmatic Relations
1. どんなもの?
文脈および感情値などの条件を考慮した単語置き換えでdata augmentationを実現するContextual Augmentationを提案
2. 先行研究と比べてどこがすごいの?
ニューラルネットベースのモデルは高い精度を示すが過学習しやすい。 Data augmentationは汎化性能を向上させるテクニックであり、画像認識分野では回転やフリップなどを用いてデータのかさ増しを行っている。
しかしながら自然言語処理に対するdata augmentationの適用法は限られている。 一般的にはWordNetなどを用いた単語の置き換えやルールベースの手法が用いられるが、ドメインに特化している場合も多く、一般性が失われたものとなっている。
本研究ではbi-directional言語モデル(LM)を用いて、文脈を考慮した単語置き換えでdata augmentationを実現するContextual Augmentationを提案している。
3. 技術や手法の”キモ”はどこにある?
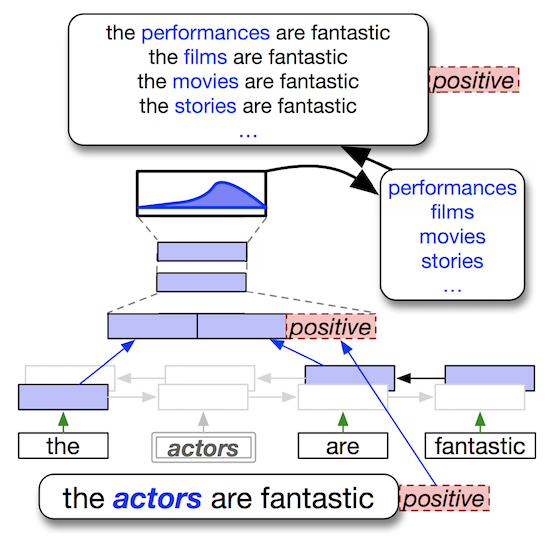
- 文脈を考慮した単語予測
- bi-directional LSTMを用いて、文脈に基づいて文中の位置 におけるword probabilityを計算
- オンラインでdata augmentationするための単語をサンプリングする
- data augmentationを制御するパラメータとしてtemperature を導入する
- 感情値などの条件を考慮
- LMにおいて
goodとbadは近い表現になりやすく、反義語がdata augmentationに使われてしまう場合がある- label-conditional LMを用いてpositive/negativeなどのラベルを考慮し、反義語を制御する
- LMにおいて
4. どうやって有効だと検証した?
SST(SST2, SST5)、Subj、MPQA、RT、TRECの各データセットを用いている。モデルはLSTM、CNNをそれぞれ利用し、提案手法であるContextual Augmentationの効果を確認している。
5. 議論はあるか?
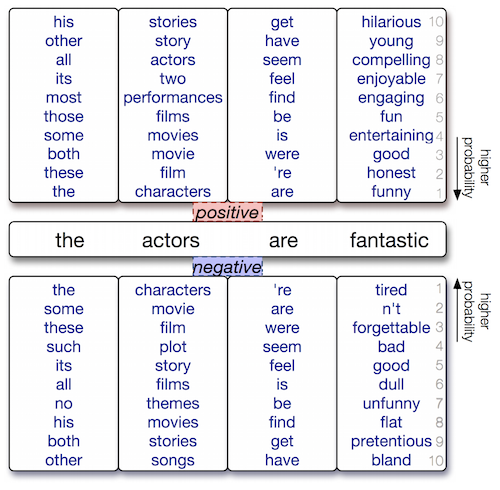
- LMによって予測された単語は必ずしもシノニムになっていない
- label-conditional LMを用いると、ラベルの性質に沿った単語の予測がなされている
6. 次に読むべき論文はあるか?
- シノニムを利用した単語置換によるdata augmentation
- Zhang, Xiang, Junbo Zhao, and Yann LeCun. “Character-level convolutional networks for text classification.” Advances in neural information processing systems. 2015.
- Wang, William Yang, and Diyi Yang. “That’s So Annoying!!!: A Lexical and Frame-Semantic Embedding Based Data Augmentation Approach to Automatic Categorization of Annoying Behaviors using# petpeeve Tweets.” Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. 2015.
- 文法推論 (grammar induction)を用いたdata augmentation
- タスク固有のヒューリスティックを利用したdata augmentation
- Fürstenau, Hagen, and Mirella Lapata. “Semi-supervised semantic role labeling.” Proceedings of the 12th Conference of the European Chapter of the Association for Computational Linguistics. Association for Computational Linguistics, 2009.
- Kafle, Kushal, Mohammed Yousefhussien, and Christopher Kanan. “Data augmentation for visual question answering.” Proceedings of the 10th International Conference on Natural Language Generation. 2017.
- Silfverberg, Miikka, et al. “Data Augmentation for Morphological Reinflection.” Proceedings of the CoNLL SIGMORPHON 2017 Shared Task: Universal Morphological Reinflection (2017): 90-99.
- Autoencoderを用いたdata augmentation
- Bergmanis, Toms, et al. “Training Data Augmentation for Low-Resource Morphological Inflection.” Proceedings of the CoNLL SIGMORPHON 2017 Shared Task: Universal Morphological Reinflection (2017): 31-39.
- Xu, Weidi, et al. “Variational Autoencoder for Semi-Supervised Text Classification.” AAAI. 2017.
- Hu, Zhiting, et al. “Toward controlled generation of text.” International Conference on Machine Learning. 2017.
- Encoder-Decoderを用いたdata augmentation
- 本研究に一番近い立ち位置の先行研究
- Kolomiyets, Oleksandr, Steven Bethard, and Marie-Francine Moens. “Model-portability experiments for textual temporal analysis.” Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies: short papers-Volume 2. Association for Computational Linguistics, 2011.
- Fadaee, Marzieh, Arianna Bisazza, and Christof Monz. “Data augmentation for low-resource neural machine translation.” arXiv preprint arXiv:1705.00440 (2017).