Hierarchical Attention Networks for Document Classification
1. どんなもの?
Attentionを用いてより重要な単語・文に注目させ、同時に文書の階層的構造を捉えることができるHierarchal Attention Network (HAN) を提案
2. 先行研究と比べてどこがすごいの?
一般的にテキスト分類をする場合、全ての単語が文書の意味を捉えるのに重要であるとは限らない。
本研究では単語レベル、文レベルでAttentionを適用することにより重要な単語および文を抽出し、 同時に文書の階層的な構造を捉えることができるHierarchal Attention Network (HAN) を提案している。
3. 技術や手法の”キモ”はどこにある?
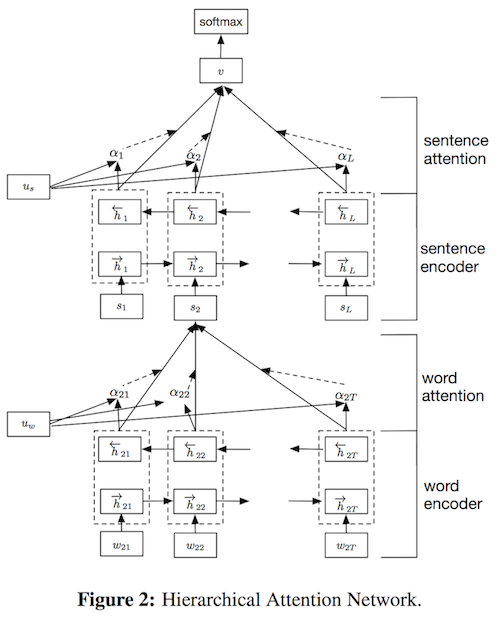
GRUによってエンコードされたembeddingに対して、単語レベル、文レベルの2つのレベルでAttentionを適用する。
- Hierarchal Attention Network (HAN)
- GRU-based sequence encoder
- Word Encoder
- Sentence Attention
- Hierarchal Attention
- Word Attention
- Sentence Encoder
- GRU-based sequence encoder
Attentionの計算はエンコードされたベクトルに対して1層のMLPを用いて隠れ層ベクトルの重要度を算出する。
4. どうやって有効だと検証した?
複数のデータセットと複数のベースラインを用いて提案手法であるHANの性能を評価している。 Attentionの効果を見るため、Hierarchal Network(HN)にaverage-poolingを使うHN-AVE、およびmax-poolingを使うHN-MAX、そして提案手法であるHNにAttentionを組み込んだHN-ATTの性能についても比較している。
データセットについて
| Data set | # of classes | # of documents | Author |
|---|---|---|---|
| Yelp 2013 | 5 | 335,018 | Tang et al., 2015 |
| Yelp 2014 | 5 | 1,125,457 | Tang et al., 2015 |
| Yelp 2015 | 5 | 1,569,264 | Tang et al., 2015 |
| IMDB review | 10 | 348,415 | Diao et al., 2014 |
| Yahoo Answer | 10 | 1,450,000 | Zhang et al., 2015 |
| Amazon review | 5 | 3,650,000 | Zhang et al., 2015 |
ベースラインについて
- Linear methods
- BoW and BoW + TFIDF
- n-grams and n-grams + TFIDF
- Bag-of-means
- SVMs
- Text Features
- Average SG
- SSWE
- Neural Network methods
- CNN-word
- CNN_char
- LSTM
- Conv-GRNN
- LSTM-GRNN
- Hierarchal Network
- HN-AVE
- HN-MAX
5. 議論はあるか?

Figure 5の最初の文書でホタテを気に入らないような文章がある場合、単文だけを見ると、これは否定的なコメントだと感じられる。 しかし、提案手法ではこの文章の文脈を見て、これが肯定的な評価であり、この文を無視することを選択していることが示されている。
6. 次に読むべき論文はあるか?
- Attentionについて
- Bahdanau, Dzmitry, Kyunghyun Cho, and Yoshua Bengio. “Neural machine translation by jointly learning to align and translate.” arXiv preprint arXiv:1409.0473 (2014).
- Xu, Kelvin, et al. “Show, attend and tell: Neural image caption generation with visual attention.” International Conference on Machine Learning. 2015.