Utilizing Visual Forms of Japanese Characters for Neural Review Classification
1. どんなもの?
文字の見た目を考慮した文字embeddingを用いて日本語の評判分析を行う
2. 先行研究と比べてどこがすごいの?
日本語や中国語の文字は表意文字であり、文字自身が意味を持っている。通常の自然言語処理の手法では、文字の見た目の情報は無視し、文字IDの羅列として扱う。 本研究では表意文字や記号の形状を考慮した日本語の評判分析を行うモデルを提案している。
3. 技術や手法の”キモ”はどこにある?
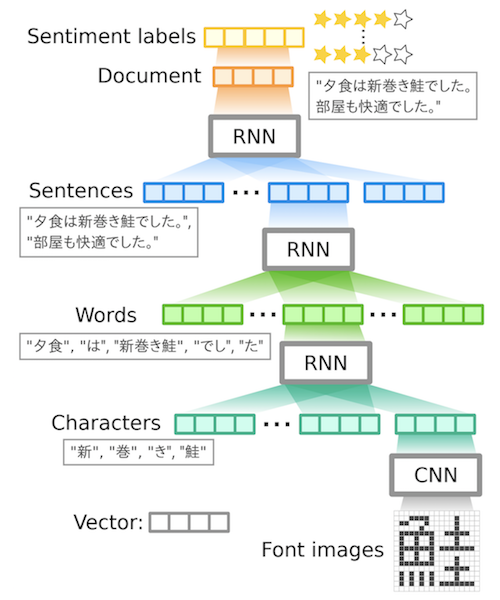
- Character-based Hierarchal Attention Networks (HAN) をベースとしたモデル
- HANと比べて文字embeddingのパラメータ数が大幅に減少している
- 文字を文字画像に変換し、そこからConvolutional Neural Networks (CNN) を通して文字の形状情報を捉えた文字embeddingを取り出す
4. どうやって有効だと検証した?
6段階の評価と7カテゴリが付与されているRaluten Travel reviewを用いて提案手法の性能を評価している。 ベースラインとして先行研究のHANを利用し、前処理としてneologdnを用いてNFKCのユニコード標準化を行っている。
5. 議論はあるか?
- Visual attentionを適用して評判分析の際に文字のどの部分に着目しているのか可視化したい
- 従来の部首の辞書を用いた特徴を利用すれば未知の文字に対しても有効に特徴を取得できるのではないだろうか