Realistic Evaluation of Semi-Supervised Learning Algorithms
1. どんなもの?
現在SoTAである半教師あり学習のアルゴリズムについて、平等なテスト環境で性能を比較した。
2. 先行研究と比べてどこがすごいの?
Deep neural networkを学習させるためには大量の教師データが必要になるが、実際はデータが取りづらかったり、コストがかかる。 そこで教師ラベルのないデータセットも有効に活用する、半教師あり学習(SSL)が提案されている。
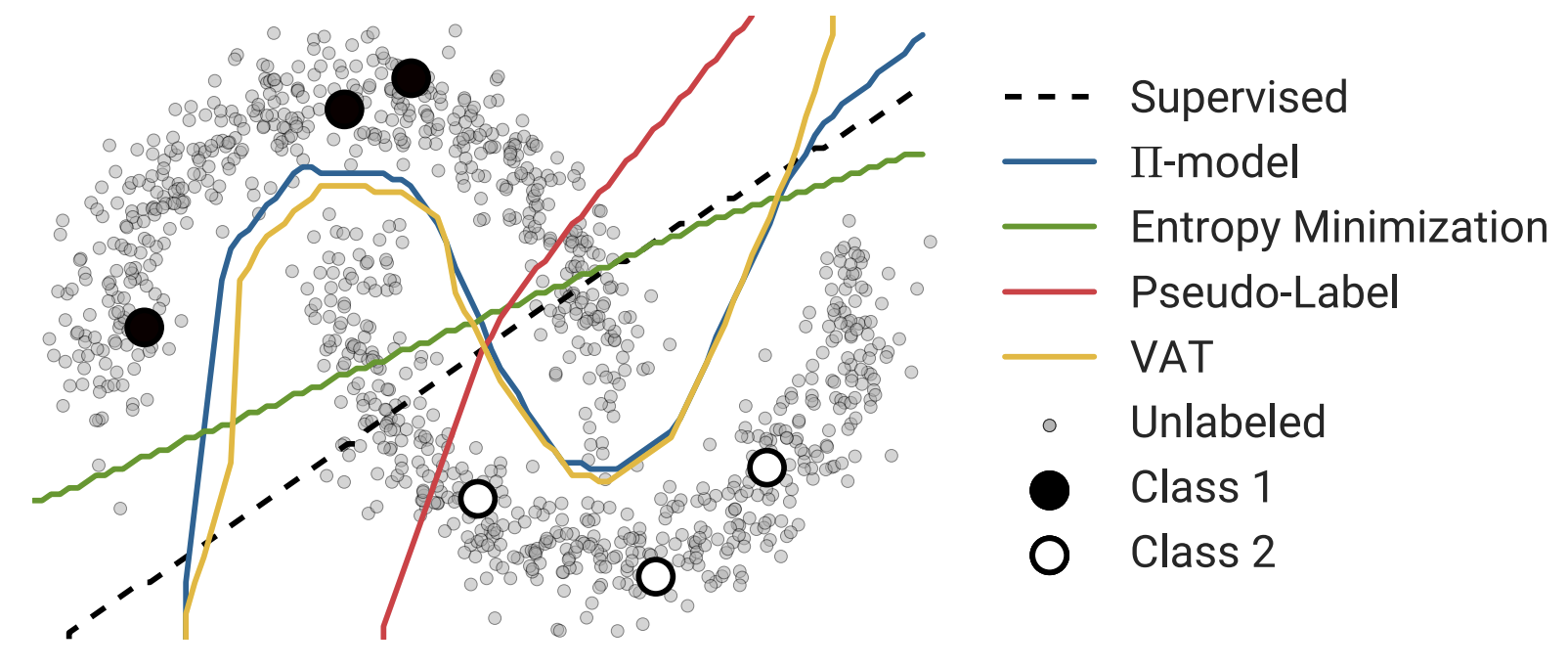
先行研究で成果を上げているモデルは実際の使用環境を想定したモデルになっているかが疑問点としてあげられている。 本研究では現在デファクトスタンダートである半教師あり学習アルゴリズムに対して、それぞれ現実世界を想定した平等なテスト環境で性能を比較している。
3. 技術や手法の”キモ”はどこにある?
従来の半教師あり学習の評価方法を見直し、現実世界での適用を想定した以下の評価方法を用いて先行研究のモデルを評価した。
- Shared Implementation
- パラメータの初期化方法やデータの前処理、augmentation、正則化等を標準化する
- High-Quality Supervised Baseline
- SSLのゴールは と を用いて学習させたモデルが、 のみを用いて学習したモデルより良い精度を出すことである
- そこで比較対象であるベースラインのモデルは のみを用いて学習させるべき
- ベースラインのモデルのパラメータ探索もSSLモデルと同様の回数探索するように設定
- Comparison to Transfer Learning
- 学習済みモデルをfine-tuningした結果はあまり報告されないので、本研究ではベースラインとして精度を報告する
- Consider Class Distribution Mismatch
- ラベル付きデータとラベルなしデータの分布の違いによる影響について報告する
- Varying the Amount of Labeled and Unlabeled Data
- ラベルなしデータは巨大である(インターネット上から取得)場合か、医療画像のようにデータの規模が小さい場合が考えられる
- Realistically Small Validation Set
- 先行研究ではtrainingセットの中から一部ラベルを落としたデータを用いて学習させ、validationセットでモデルのチューニングをしていた。このときラベル有りデータの数はvalidationセットのほうが遥かに多い
- 現実世界ではラベルを多く含むデータセットで学習を行うため、先行研究の評価方法では実践的な評価ができていないため、本研究ではtrainingセットより小さいvalidationセットを用いてパラメータをチューニングする
4. どうやって有効だと検証した?
使用したSSLアルゴリズムについて
| Method | Type | Author |
|---|---|---|
| Stochastic Perturbations | Consistency Regularization | Sajjadi et al., 2016 |
| Ⅱ-Model | Consistency Regularization | Laine & Aila, 2017 |
| Temporal Embsembling | Consistency Regularization | Laine & Aila, 2017 |
| Mean Teacher | Consistency Regularization | Tarvainen & Valpola, 2017 |
| Virtual Adversarial Training | Consistency Regularization | Miyato et al., 2017 |
| Entropy-Based | Entropy-Based | Grandvalet & Bengio, 2005 |
| Pseudo-Labeling | Pseudo-Labeling | Lee, 2013 |
評価方法について
- Reproduction
- ベースモデルにWide ResNet (WRN-28-2) を使用
- Google Cloud Machine Learning’s hyperparameter tuning serviceを用いてGaussian Process-based black box optimizationを行った
- 評価用データセットとしてSVHNとCIFAR-10を使用
- Fully-Supervised Baselines
- Transfer Learning
- Class Distribution Mismatch
- Varying Data Amounts
- Small Validation Sets
5. 議論はあるか?
- SSLの各アルゴリズムに対して分布が違うラベルなしデータを学習に使うと学習が上手く進まなかった
- ラベルありデータと同様の分布からサンプリングされるラベルなしデータを使用すべきである
6. 次に読むべき論文はあるか?
- Stochastic Perturbationsについて
- Ⅱ-Model / Temporal Ensemblingについて
- Mean Teacherについて
- Virtual Adversarial Trainingについて
- Entropy-basedな手法について
- Pseudo-Labelingについて