Word Embedding Perturbation for Sentence Classification
1. どんなもの?
入力される単語embeddingに対していくつかのノイズで摂動を与え、文書分類における精度の検証する
2. 先行研究と比べてどこがすごいの?
自然言語処理では単語は離散的であり、連続空間では単語表現を変更できないため、一般的にdata augmentationは利用されてこなかった。
近年ではシソーラスを用いた単語の置換や、2つの単語間の依存関係の向きを逆にすることで学習データを2倍に増やす手法が提案されている。これらは外部の知識体系が必要であったり、洗練されたNLPツールが必要である。
またBag-of-Wordsに対してランダムにdropoutさせる手法を用いて、文書分類で性能を向上させたものがある。しかしながらノイズの与え方を比較していなかったり、単語の分散表現空間に対して適用していない問題がある。
本研究では連続空間上の単語embeddingに対して複数種類のノイズで摂動を与え、文書分類における精度の検証を行っている。
3. 技術や手法の”キモ”はどこにある?
Word embeddingレイヤーに対して word embedding perturbation を適用。
- Gaussian Noise
- 入力される単語embeddingに対して、ガウスノイズ を適用する
- Bernoulli Noise Augmentation
- 先行研究で提案されているDropoutを参考に、確率 で単語embeddingを0にする
- Adversarial Training
- loss関数が最大になるような方向にノイズを加える
文書の意味を考慮したrandom perturbationについて。
- Word Dropout
- ベルヌーイ分布に従ってランダムに単語 をdropoutさせる
- dropoutさせた単語は
UNKと同じ表現にする
- Semantic Dropout
- 単語embeddingの各次元はそれぞれセマンティックな意味を持っていると考えられる
- 単語間の共起を覚えさせるのではなく意味的な特徴を捉えてほしいため、単語embeddingの各次元をランダムにdropoutさせる
- Adversarial Noise
- Gaussian adversarial noise
- ガウス分布から をサンプルして、adversarial trainingを適用
- Bernoulli adversarial noise
- ベルヌーイ分布から をサンプルして、adversarial trainingを適用
- Adversarial dropoutを適用
- Gaussian adversarial noise
4. どうやって有効だと検証した?
Moview review (MR)、The Stanford Sentiment Treebank (SST2)、Customer revirew (CR)、Question type (TREC)、SemEval2010 Task8 (RE)、Answer selection (TreeQA) の データセットを用いてノイズを用いた各data augmentationの効果を確認している。
モデルはmulti-channel CNN (Kim, 2014)を利用しており、300次元の学習済みword2vecを単語embeddingとして用いている。
5. 議論はあるか?
- 連続性ノイズと離散性ノイズ
- 連続性ノイズ (Gaussian noise, Gaussian adversarial noise) のほうが僅かに離散性ノイズ (Bernoulli noise, Adversarial dropout) より良い結果になった
- 離散性ノイズは効果が強すぎたと考えられる
- 連続性ノイズのほうがエントロピーが大きく、学習に効果があると考えられる
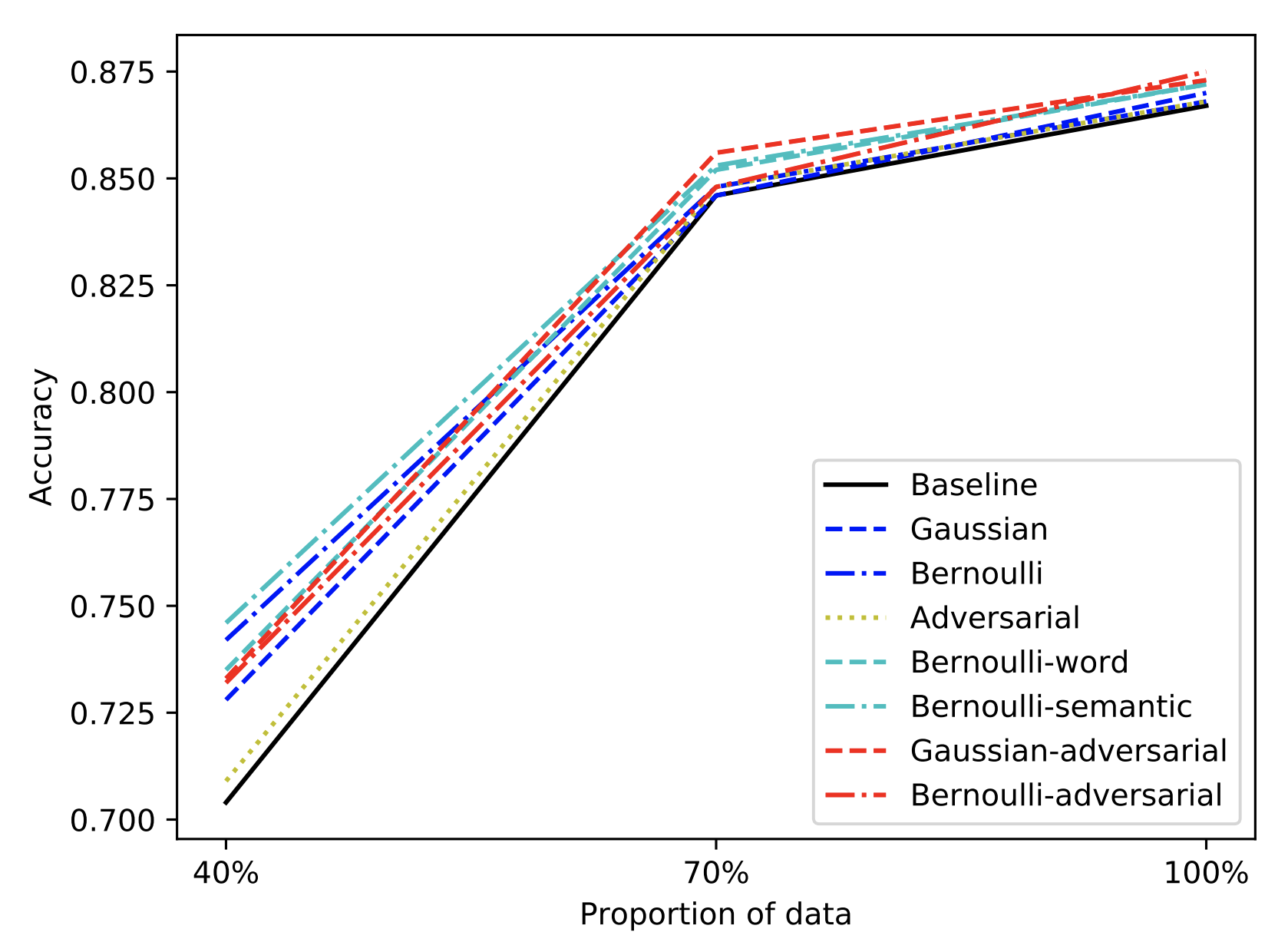
- 学習データを少なくしたときの効果
- データセットが少ない場合に、ベースラインよりもノイズの摂動が効果を発揮していることが分かる
6. 次に読むべき論文はあるか?
- シソーラスを用いた単語の置換
- 単語間の依存関係に着目したdata augmentation
- BoWに対してdropoutを適用
- Iyyer, Mohit, et al. “Deep unordered composition rivals syntactic methods for text classification.” Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Vol. 1. 2015.
- Zhang, Dongxu, Tianyi Luo, and Dong Wang. “Learning from LDA using deep neural networks.” Natural Language Understanding and Intelligent Applications. Springer, Cham, 2016. 657-664.
- Adversarial Dropout
- ベースラインの multi-channel CNN