A New Method of Region Embedding for Text Classification
1. どんなもの?
CNNやRNNを必要とせずに語順を考慮することができるLocal Context Unitを利用し、タスク固有の単語埋め込み表現を学習するRegion Embeddingを提案。
2. 先行研究と比べてどこがすごいの?
文書分類などのタスクにおいて単語の語順を考慮した単語表現にn-gramが用いられることが多いが、 特に の値が大きいn-gramの場合、モデルが大きくなってしまったり、データスパースネス問題が起こる恐れがある。
近年ではn-gramを考慮した単語の分散表現を獲得するFastTextが提案されている。 またJohnson & Zhang (2015)では CNNベースのモデルを用いて単語表現を獲得するregion embeddingという手法を提案しているが、本研究のregion embeddingとは異なり、タスク依存でない点や、教師なし学習の枠組みで学習されている点で異なっている。
Attentionのみを使用したニューラル機械翻訳モデルであるTransformerは、CNNやRNNを用いずに語順を考慮し、文脈の特徴を学習できていることが示されている。
本研究ではTransformer参考に、ある単語の周辺のコンテキストを考慮できるLocal context unitを用いて単語の埋め込み表現を獲得するRegion Embeddingを提案し、文書分類タスクで精度が上がることを示している。
3. 技術や手法の”キモ”はどこにある?
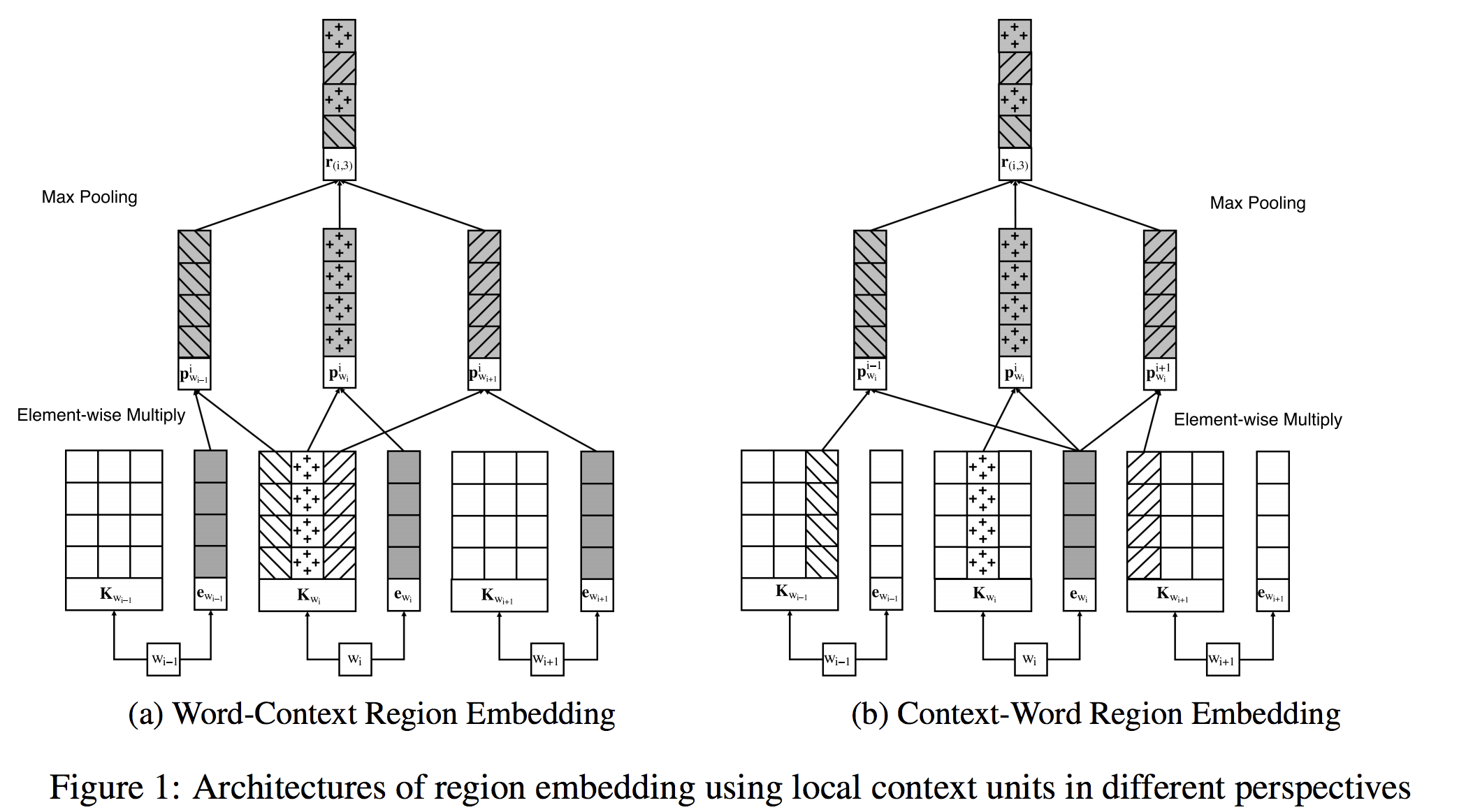
- Region Embedding
- テキスト中の小さな範囲(region)から、局所的な特徴を保持した表現を獲得したい
- Local Context Unit
- ある単語の語順と周辺のコンテキストを学習するパラメータ
- 通常のlook up tableを用いたword embedding とlocal context unit を組み合わせた埋め込み表現 を学習する
- Word-Context Region Embedding
- regionの中心の語が前後のコンテキストから受ける影響に焦点を当てたemnedding手法
- 語の出現順によって(特に否定語や強調語など)、意味が逆転する場合を上手く学習することを期待
- Context-Word Region Embedding
- Word-Context Region Embeddingとは逆に、コンテキストがregionの中心語から受ける影響に焦点を当てている
- Region Embeddingを全結合層で分類
4. どうやって有効だと検証した?
8つのデータセットを用いて感情分析、新聞記事分類、QAなどのタスクに対して精度を比較している。 ベースラインのn-gram・TFIDFなどの従来の単語表現を用いたモデル、Char-CNN、Char-CRNN、VDCNN、D-LSTM、bigram-FastTextと先行研究のRegion Embeddingを用いた分類器を比較している。 8つのデータセットのうち6つのデータセットで最先端の結果を達成していることが示されている。
5. 議論はあるか?
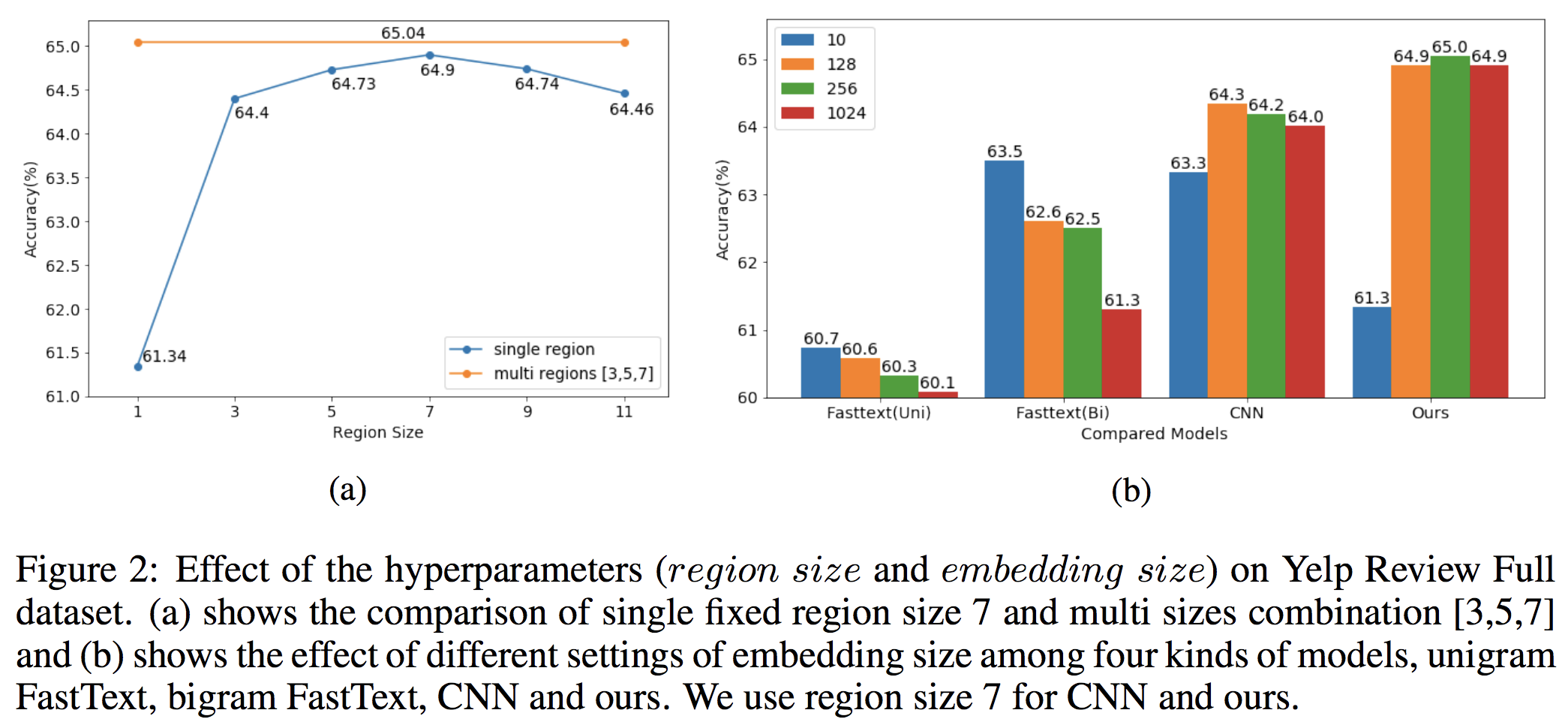
- region size / embedding sizeを変えた場合について
- 本研究ではregion sizeを7、embedding sizeを128に設定している
- 複数サイズのregion embeddingを組み合わせることで僅かに精度が向上している
- emnedding sizeを大きくすると従来のFastTextやCNNなどは過学習が見られるが、Region Embeddingはほかと比べてロバストであることが示されている
- ある単語における周辺単語の共起について
- “however”についてはhoweverの後が文書分類に重要であることを示している
- “very”についてはveryの直後の語が重要である etc
- local context unitが局所的な潜在意味を捉えていることが分かる

- 感情分析におけるlocal context unitの効果の可視化
- context unitがある場合、正しく形容詞が正しく係り、positive/negativeの判定が正しく行われるようになったことが示されている
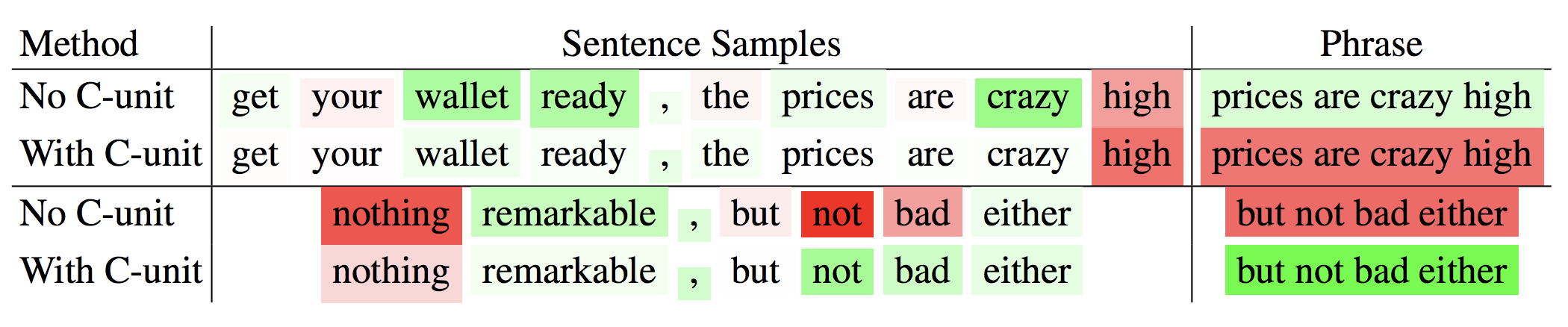
- context unitがある場合、正しく形容詞が正しく係り、positive/negativeの判定が正しく行われるようになったことが示されている
6. 次に読むべき論文はあるか?
- FastTextを用いたembeddingについて
- CNNを用いたembeddingについて
- Transformerについて
- ベースラインのモデルについて
- Char-CNNについて
- Char-CRNNについて
- VDCNNについて
- D-LSTMについて
- 予測における寄与単語の可視化について