Glyph-aware Embedding of Chinese Characters
1. どんなもの?
漢字特有の文字の表意性を明示的に組み込み,文字形状を意識した文字の埋め込み手法を提案.
2. 先行研究と比べてどこがすごいの?
英語と比べて中国語は多数の文字が使用され,なおかつ単語と単語の境目が明確ではない. 漢字には形状的な特徴があり,特に”へん”や”つくり”などの部分的な構造が集まり,それら自身が文字の意味・構文的役割・発音などの情報を有している.
本研究ではこれら漢字の文字形状に着目することで,優れた文字表現の獲得を目指す glyph-aware embedding を提案している.
3. 技術や手法の”キモ”はどこにある?
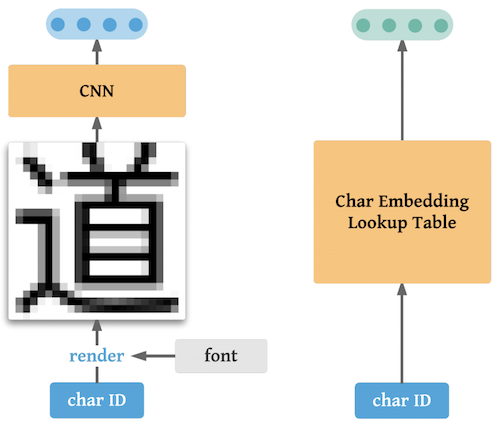
- CNN embedder
- 文字形状を考慮した文字の埋め込みをCNNを用いて実現
- ID embedder
- 文脈を考慮した文字の埋め込みをLookup tableを用いて実現
文字形状のみ考慮した場合,「土」⇆「士」や「人」⇆「入」といった文字形状が似ている文字が近い表現となってしまう場合が考えられる. そこで文脈を考慮できるLookup tableによるID embeddingを併せて用いることで,この問題を解消している.
4. どうやって有効だと検証した?
中国語の言語モデリングタスクと中国語の単語分割タスクについて提案手法の精度を検証している.
- 言語モデリングタスク
- embedderで文字表現を得た後,後段のGRUで言語モデルタスクを解いている
- ベースラインとして全結合層のみからなるlinear embedderを設定
- Microsoft Research dataset (MSR) を用いて,CNN embedder・ID embedder・ID+CNN embedderそれぞれのperplexityを比較している
- 単語分割タスク
- embedderで文字表現を得た後,後段のGRU/Bidirectional LSTMで単語分割タスクを解いている
- Peking University dataset (PKU) および MSRを用いて,CNN embedder・ID embedder・ID+CNN embedderそれぞれの精度を比較している
各タスクともCNN embedderが優れた性能を示している.
5. 議論はあるか?
- 入力文字画像にdata augmentationを加えることで精度が向上
- CNN embedder / ID embedderのパラメータ数について
- 埋め込み次元 ,ボキャブラリサイズ の場合
- CNN embedder:
- ID embedder:
- CNN embedderのほうがID embdderよりも少ないパラメータ数で良いパフォーマンスを出していることが分かる
6. 次に読むべき論文はあるか?
- Shi, Xinlei, et al. “Radical embedding: Delving deeper to chinese radicals.” Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 2: Short Papers). Vol. 2. 2015.
- Liu, Frederick, et al. “Learning character-level compositionality with visual features.” arXiv preprint arXiv:1704.04859 (2017).
- Costa-Jussà, Marta R., David Aldón, and José AR Fonollosa. “Chinese–spanish neural machine translation enhanced with character and word bitmap fonts.” Machine Translation 31.1-2 (2017): 35-47.