Component-Enhanced Chinese Character Embeddings
1. どんなもの?
中国語における漢字の部首を元に、文字単位の埋め込み表現を学習する。
2. 先行研究と比べてどこがすごいの?
先行研究では単語単位で埋め込み表現を学習するContinuous Bag-of-Words(CBOW)モデルやSkip-gramモデルが有名である。
英語と異なり「漢字」は表意文字であり、「1文字」が意味をなす最小の意味単位であることに注目し、漢字の文字構成から意味表現を獲得しよう考えたのが本研究である。
3. 技術や手法の”キモ”はどこにある?
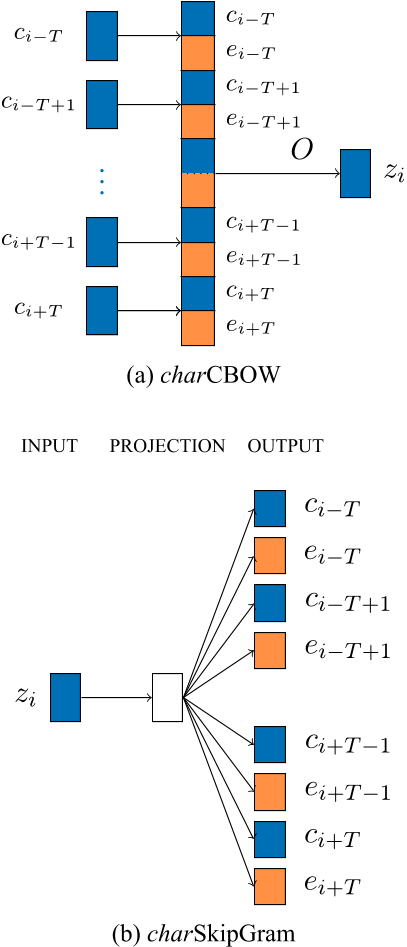
- CBOWやSkip-gramを文字レベルで適用した「charCBOW」・「charSkipGram」
- 学習した文字表現をbi-gramのように2つ組み合わせた「charCBOW-bi」・「charSkipGram-bi」
4. どうやって有効だと検証した?
本研究で学習した文字表現を利用して、文字の類似度タスクと文書分類タスクで評価を行っている。
文字表現の学習にはChinese Wikipediaデータセットを用いている。
文字の類似度タスクではHIT-CIR’S Extended Tongyici Cilin(E-TC)を用いて、Spearman’s rank correlationを指標に評価を行っている。
文書分類タスクではTencent news titlesデータセットを用いて、事前に学習した文字表現を元にロジスティック回帰を使って分類を行っている。
5. 議論はあるか?
- 文書分類タスクにおいて、すべての数値でcharCBOW-biが最も優れたスコアを出している。
- 中国語の単語の大半は2文字程度から構成されているため、2文字分の文字表現を連結しているcharCBOW-biが良い結果を出していることに頷ける。
- uni-gramとbi-gramの文字表現を組み合わせた文字表現(charCBOW-combine)を使って文書分類をを行ったところ、8.4%程度精度が向上している。
6. 次に読むべき論文はあるか?
CBOW・Skip-gramについて
Spearman’s rank correlationについて