A Comprehensive Survey on Cross-Modal Retrieval
1. どんなもの?
画像やテキストといった複数の要素を用いた「クロスモーダル検索」について、最新の研究にフォーカスをして調査を行っている。
2. 先行研究と比べてどこがすごいの?
近年の携帯端末やSNSの発展により、写真を中心とした画像やテキスト、動画といったマルチモーダルなデータが多数生成されている。こういったデータを検索する方法は、ほとんどが「テキストからテキストを検索する」「画像から画像を検索する」といった同じタイプのデータに対してのみに行われてきている。
本調査では違うタイプのメディア同士を検索を行うことができ、重要となりつつある「クロスモーダル検索」について複数の手法について調査を行っている。
3. 技術や手法の”キモ”はどこにある?
一般的に画像やテキスト、動画といったマルチモーダルなデータに対してそれぞれに適した方法を使って特徴量を取得し、それらの特徴量を元に共通の表現空間を学習することで、クロスモーダルな検索を可能にする。
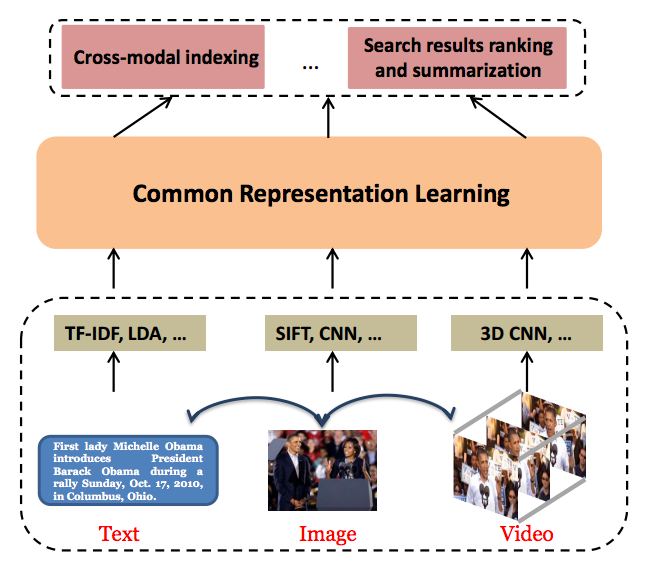
クロスモーダル検索に対するアプローチとして、大きく「Real-valued Representation Learning」と「Binary Representation Learning」の2つのカテゴリに分けることができる。
またそれぞれ異なるメディアについての共通の表現空間を学習する方法として「Unsupervised Methods」「Pairwise Based Methods」「Rank Based Methods」「Supervised Methods」の4つの手法に分けられる。
これらの手法についての概要は以下のようになる。
Real-valued Representation Learning
Unsupervised Methods
Subspace learning methods
- Canonical Correlation Analysis (CCA)
- Partial Least Squares (PLS)
- Bilinear Model (BLM)
- Cross-modal factor analysis (CFA)
- Maximum covariance unfolding (MCU)
- Collective component analysis (CoCA)
- Maximum Mean Discrepancy (MMD)
Topic model
- Correspondence LDA (Corr-LDA)
- Topic-regression Multi-modal LDA (Tr-mm LDA)
- Multi-modal Document Random Field (MDRF)
Deep learning methods
- Multimodal Deep Autoencoder
- Ngiam et al.
- 口の動きの動画とスピーチ音声のペアの情報から共通の表現を学習。
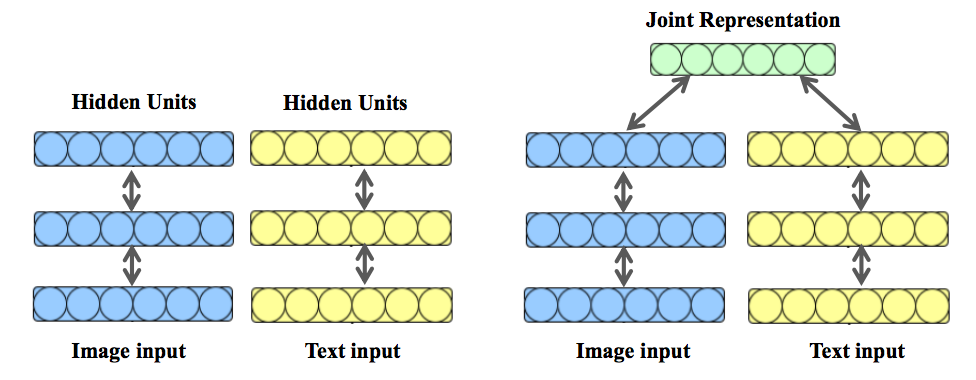
- Multimodal Deep Restricted Boltzmann Machine (Multimodal DBM)
- Srivastava and Salakhutdinov
- はじめに各モダリティそれぞれの低次元の表現を学習し、最終層で各モダリティの表現を結合し1つのベクトルとしている。
- Deep Canonical Correlation Analysis (DCCA)
- Andrew et al.
- Deep Learning手法からインスパイアを得たもので、異なるモダリティのデータに対して複雑な非線形射影を学習する方法。
- End-to-end DCCA
- Yan and Mikolajczyk
- DCCAをEnd-to-Endの学習スキームへと発展させている。

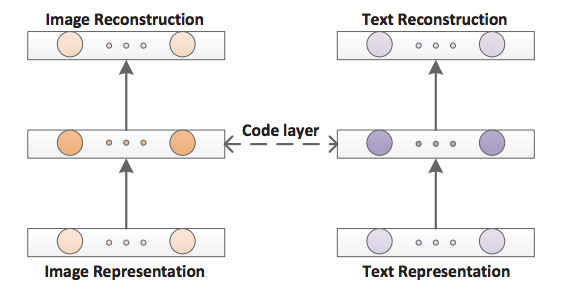
- Correspondence AutoEncoder (Corr-AE)
- Feng et al.
- 画像・テキストそれぞれに対してAutoEncoderを用意し、隠れ層での表現を相関させるように学習させる。
- 表現学習のエラーと相関学習のエラーを最小化するようにパラメータを変更。
- Joint Video-Language Model
- Xu et al.
- 3つのモデルで構成されている。
- Compositional Semantics Language model
- Deep Video Model
- Joint Embedding Model
- 視覚的に認識をする部分と語の順序を保持する、画像とテキストのクロスモーダル的なモデルを提案。
- 映像から言語を、言語から映像を検索することを可能にしている。
Pairwise based methods
Shallow methods
- Multi-View Neighborhood Preserving Projection (Multi-NPP)
- MultiView Metric Learning with Global consistency and Local smoothness (MVML-GL)
- Joint Graph Regularized Heterogeneous Metric Learning (JGRHML)
Deep learning methods
- Relational Generative Deep Belief Nets (RGDBN)
- Modality-Specific Deep Structure (MSDS)
Rank based methods
Shallow methods
- Supervised Semantic Indexing (SSI)
- Passive-Aggressive Modal for Image Retrieval (PAMIR)
- Latent Semantic Cross-Modal Ranking (LSCMR)
- Bi-directional LSCMR (bi-LSCMR)
- Wsabie
- Ranking Canonical Correlation Analysis (RCCA)
Deep learning methods
- Deep Visual-Semantic Embedding (DeViSE)
- Dependency Tree Recursive Neural Networks (DT-RNNs)
- Deep Fragment
- Deep Compositional Cross-Modal Learning (C2MLR)
Supervised methods
Subspace leraning methods
- Common Discriminant Feature Extraction (CDFE)
- Generalized Multiview Analysis (GMA)
- Intra-view and Interview Supervised Correlation Analysis (I2SCA)
- Parallel Field Alignment Retrieval (PFAR)
- Joint Representation Learning (JRL)
- Supervised coupled dictionary learning with group structures for multi-modal retrieval (SliM2)
- Cluster Canonical Correlation Analysis (cluster-CCA)
- Three-View CCA (CCA-3V)
- Learning Coupled Feature Spaces (LCFS)
- Joint Feature Selection and Subspace Learning (JFSSL)
Topic model
- Supervised Document Neural Autoregressive Distribution Estimator (SupDocNADE)
- NonParametric Bayesian upstreamsupervised multi-modal topic model (NPBUS)
- Supervised Multi-Modal Mutual Topic Reinforce Modeling (M3R)
Deep learning methods
- Regularized deep neural network (RE-DNN)
- Deep Semantic Match (deep-SM)
- Multi-modal Deep Neural Network (MDNN)
Binary Representation Learning
Unsupervised Methods
Linear modeling
- Cross-View Hashing (CVH)
- Inter-Media Hashing (IMH)
- Predictable Dual-view Hashing (PDH)
- Linear Cross-Modal Hashing (LCMH)
- Collective Matrix Factorization Hashing (CMFH)
- Latent Semantic Sparse Hashing (LSSH)
Nonlinear modeling
- Multi-modal Stacked AutoEncoders (MSAE)
- Deep Multimodal Hashing with Orthogonal Regularization (DMHOR)
Pairwise based methods
Linear modeling
- Cross-Modal Similarity Sensitive Hashing (CMSSH)
- Co-Regularized Hashing (CRH)
- Iterative Multi-View Hashing (IMVH)
- Quantized Correlation Hashing (QCH)
- Relation-aware Heterogeneous Hashing (RaHH)
- Heterogeneous Translated Hashing (HTH)
Nonlinear modeling
- Multimodal Latent Binary Embedding (MLBE)
- Parametric Local Multimodal Hashing (PLMH)
- Full Multimodal neural network (MM-NN)
- Correlation Hashing Network (CHN)
Supervised methods
Linear modeling
- Sparse Multi-Modal Hashing (SM2H)
- Discriminative Coupled Dictionary Hashing (DCDH)
- Semantic Correlation Maximization (SCM)
Nonlinear modeling
- Semantics-Preserving Hashing (SePH)
- Correlation Autoencoder Hashing (CAH)
- Deep Cross-Modal Hashing (DCMH)