Context-Dependent Sentiment Analysis in User-Generated Videos
1. どんなもの?
マルチモーダル (テキスト・音声・動画) における発音レベルの特徴量を用いた感情分析を行うモデルを提案
2. 先行研究と比べてどこがすごいの?
マルチモーダルを用いた感情分析を行うモデルは複数提案されてきたが、先行研究では発話レベルでの依存関係を無視したモデルのみしか提案されていなかった。
本研究では発話中の呼吸や小休止で区切り 1 つの単位とする utterance-level (発話レベル) の特徴量にフォーカスを当て、これらの系列を元にマルチモーダルの特徴を用いて感情分析を行った。
3. 技術や手法の”キモ”はどこにある?
マルチモーダル(テキスト・音声・動画)から utterance-level の特徴を抽出し、Contextual-LSTM を用いてこれらの系列を考慮した感情分析モデルを構築
発話レベルの特徴量抽出
- テキストからの特徴抽出
text-CNN- 学習済み word2vec を入力し、複数種類のカーネルを持つ 2 層の CNN でテキストのセマンティクスを抽出
- 音声からの特徴抽出
openSMILE- オープンソースのソフトウェアである openSMILE を用いて、音声のピッチや強度といった特徴量を抽出
- 動画からの特徴抽出
3D-CNN- 通常の 2D の CNN に対して時間軸方向を考慮した 3D の CNN を使用
コンテキストを考慮した特徴抽出
抽出した utterance-level の特徴量に対して、発話ごとの関係性を学習する LSTM (Contextual-LSTM) を用いる。
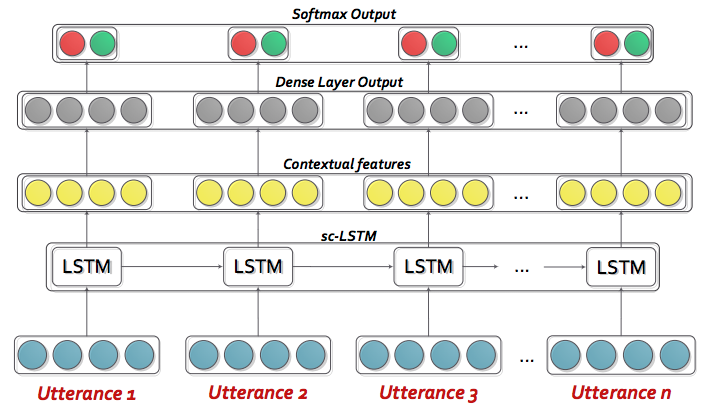
Contextual-LSTM は複数種類の LSTM を比較
sc-LSTM(simple contextual LSTM)- 順方向のみのシンプルな LSTM を使用
h-LSTM(hidden LSTM)- LSTM の後に全結合層を入れずにそのまま隠れ状態を後段に渡す
bc-LSTM(bi-directional LSTM)- 発話に対して双方向の特徴を考慮できる bi-directional LSTM を使用
uni-SVM- ベースラインとして SVM を使用
複数のモダリティ特徴を用いた感情分析
- 複数のモダリティに対して階層構造を考慮する (Hierarchical Framework)
- Level-1
- 各モダリティ (テキスト・音声・動画) の特徴量に対してそれぞれ独立で LSTM に通し、対象モダリティ独自のコンテキストをを学習
- Level-2
- Level-1 で学習した各モダリティ独立した特徴を concat して LSTM に通すことでマルチモーダルなコンテキストを学習
- Level-1 と Level-2 は end-to-end での学習ではない
- Level-1
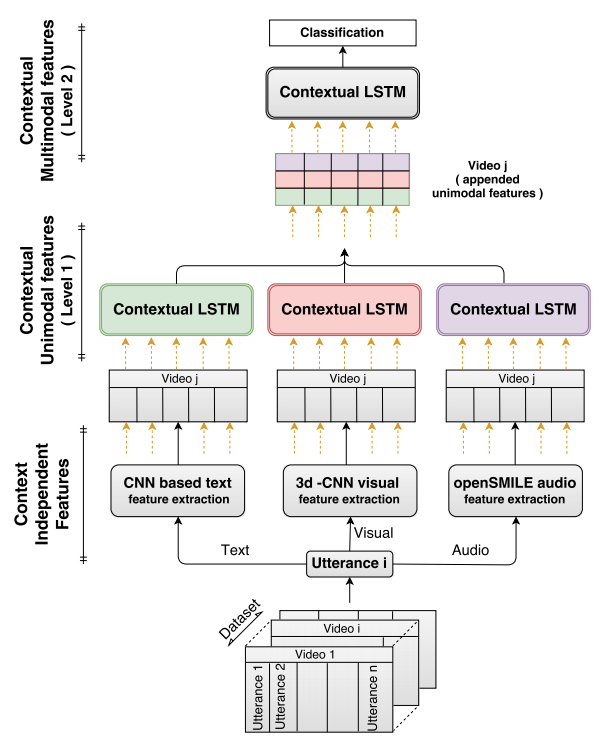
- 階層構造を考慮しない枠組み (Non-hierarchical Framework) についても比較
- 単一のモダリティ特徴を contextual-LSTM (sc-LSTM や bc-LSTM) に入力
4. どうやって有効だと検証した?
マルチモーダルな感情分析を行う先行研究の大部分の検証実験において、学習データとテストデータに同じ話者が入っている場合が多い。 話者が同じ場合であっても、感情表現やセマンティクスはデータによって異なると考えられているためである。 しかしながら感情分析に対して一般性・話者に依存しないモデリングを行うことは重要である。
本研究での検証実験では現実世界に即したアプリケーションを目指すため、未知の話者に対してもモデルがロバストになるように、 話者独立でデータセットの train/test 分割を行っている。
マルチモーダルな感情分析を検証するためのデータセットについて
MOSI
- 93 人が英語である話題についてレビューしている動画が含まれる
- 5 人のアノテーターが
-3〜+3の感情値を付与- ラベルの平均値を計算し、
positiveとnegativeの 2 クラスとして使用
- ラベルの平均値を計算し、
MOUD
- 55 人がスペイン語である製品についてレビューしている動画が含まれる
- Google Translate API を用いてスペイン語から英語に変換
- positive, negative, neutral のラベルが付与されているが、
positiveとnegativeのみ使用
IEMOCAP
- 10 人が英語で対話している動画データセット
- データセットには以下 9 つのラベルが付与されている:
anger、happiness、sadness、neutral、excitement、frustration、fear、surprise、other- 先行研究と比較するために上記最初の 4 つのクラスだけをラベルとして使用
- 8 人を学習データ、2 人をテストデータとして使用
また汎化性能を確認するため、MOSI データセットで学習したモデルを MOUD データセットで評価する cross-dataset の枠組みを導入している。
モデルのパフォーマンス比較
階層的 vs 非階層的な学習フレームワーク
- 非階層的なフレームワークはベースラインの uni-SVM を超えたが、階層的フレームワークが一番良かった
LSTM の種類の違いによる比較
- sc-LSTM、bc-LSTM ともに良い結果を出している
- bc-LSTM は順方向・逆方向のコンテキストを考慮できるため sc-LSTM より優れていた
- 全結合層がない場合 (h-LSTM) よりある場合のほうが性能は高い
ベースラインとの比較
- LSTM を用いたネットワークはすべてのデータセットに対してベースラインの uni-SVM を超える性能を出した
- 発話間の文脈依存性をモデリングすることで感情分類性のを高めている
- IEMOCAP データセットでは特にベースラインとの性能差が現れた
- より広い依存関係を適切に捉える必要があるため、LSTM ネットワークが効果的であった
- SoTA のモデルとの比較
- SoTA モデルは実験の際に話者が独立するように train/test の分割をしていない
- 発話の文脈依存を考慮していない
- 提案手法は SoTA モデルを上回る性能を示した
各モダリティの重要度
- unimodal な特徴より bimodal や trimodal な特徴を用いたほうが性能は良かった
- 音声特徴は視覚特徴よりも効果があった
- MOSI データセットと IEMOCAP データセットにおいてはテキスト特徴が有効であった
- MOUD データセットにおいてはスペイン語から英語に翻訳した影響により、テキスト特徴より音声特徴のほうが有効であった
- スペイン語の word vector を用いることでテキスト特徴における性能が向上
モデルの汎化性能について
MOSI データセットで学習を行い、MOUD データセットを用いて評価を行った。
- 音声およびテキスト特徴を用いた場合性能が低下した
- 英語のモデルでスペイン語を予測していたから
- 視覚特徴を用いた場合、音声・テキスト特徴よりも性能が良かった
- クロスリンガルであっても視覚特徴は一般的な特徴を学習できる
5. 議論はあるか?
- 発話の文脈依存を考慮できることで対象の発話を正確に分析することができている
- 音声特徴では正しく分類できない場合でも、テキスト特徴で正しく分類する例がある
- 逆に、テキストではポジティブな文脈でも、怒りっぽい音声特徴から感情を捉えてネガティブであると正しく分類する例もある
6. 次に読むべき論文はあるか?
- ベースラインについて
- Poria, Soujanya, Erik Cambria, and Alexander Gelbukh. “Deep convolutional neural network textual features and multiple kernel learning for utterance-level multimodal sentiment analysis.” Proceedings of the 2015 conference on empirical methods in natural language processing. 2015.
- Rozgic, Viktor, et al. “Ensemble of svm trees for multimodal emotion recognition.” Signal & Information Processing Association Annual Summit and Conference (APSIPA ASC), 2012 Asia-Pacific. IEEE, 2012.