Subcharacter Information in Japanese Embeddings: When Is It Worth It?
1. どんなもの?
漢字が有する部首のコンポーネントを分解し、サブキャラクターとして扱った際の言語タスクにおける性能を、新たに提案するデータセットも含めて調査を行った。
2. 先行研究と比べてどこがすごいの?
漢字は自身にへんやつくりといった複数のコンポーネントを有している。
これらサブキャラクターとして埋め込みを学習することで、中国語のいくつかの言語処理タスクで良い精度となることが報告されている。
本研究ではこうしたサブキャラクターの情報を日本語に対して適用した場合の効果を調査している。
中国語で効果のあるサブキャラクター情報が日本語においては限定的であり、 多くの場合 character-level ngram や character-level のモデルが subcharacter-level のモデルよりも良い性能を示す結果となっている。
3. 技術や手法の”キモ”はどこにある?
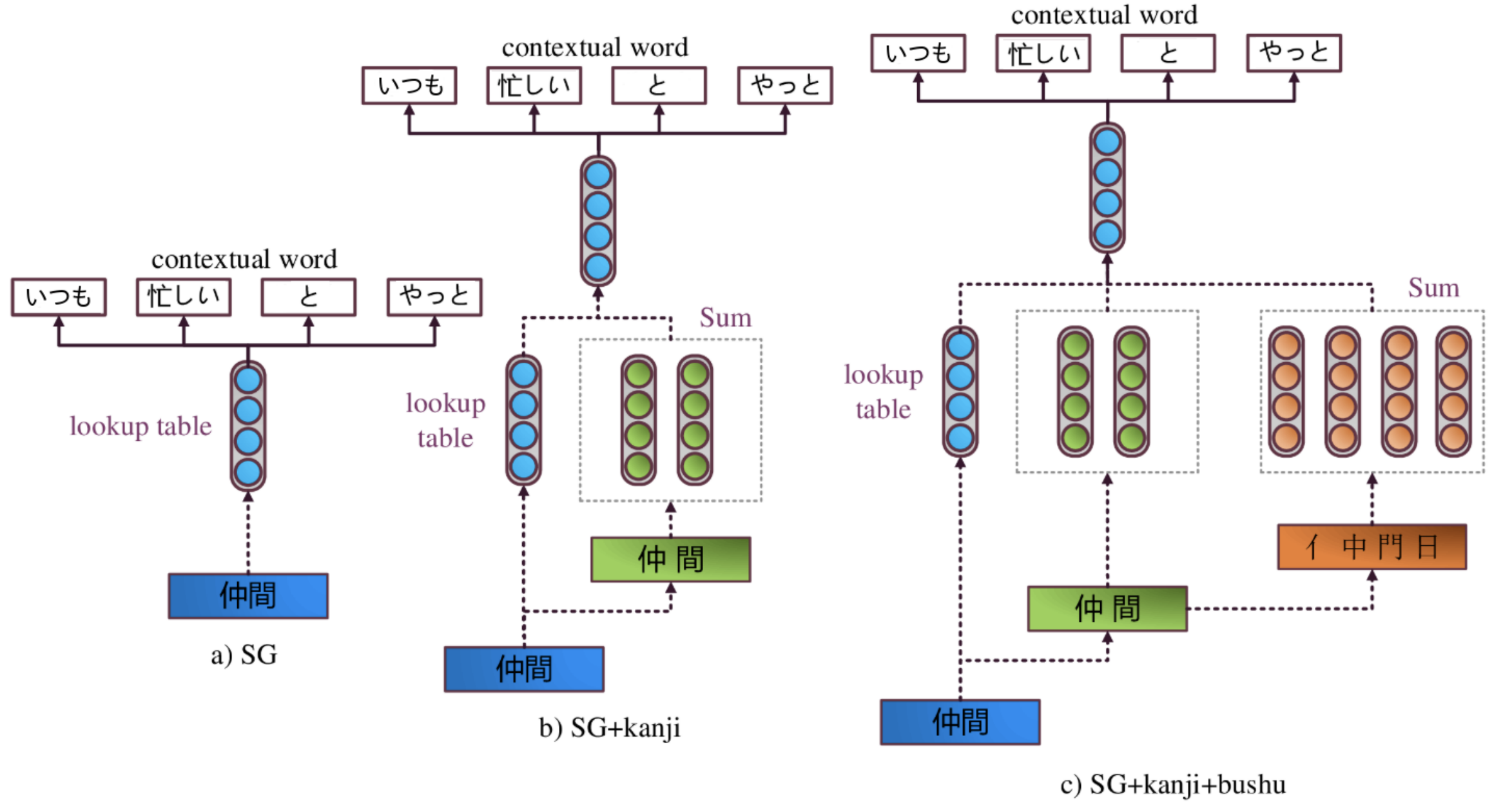
前処理
- 文字から部首を取り出す
- 部首データベースであるIDSを用いる
使用モデル
- Skip-gram + kanji モデル (character-level)
- 入力単語に対して skip-gram で得たベクトルと文字に分割して得たベクトルを用いる
- Skip-gram + kanji + bushu モデル (subcharacter-level)
- 上記のモデルに対して漢字を部首に分割して得たベクトルを用いる
評価データセット jBATS の提案
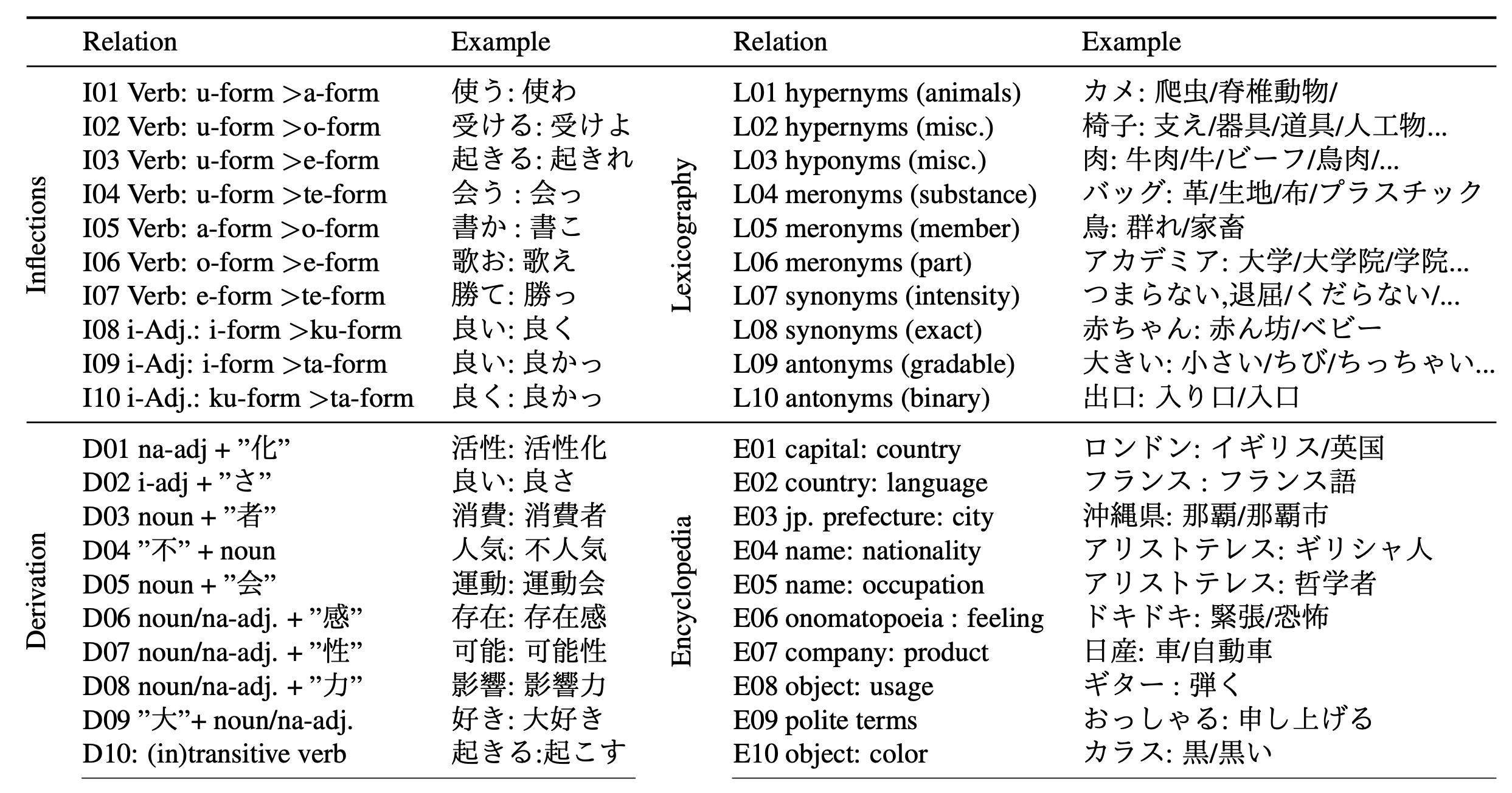
40 の言語的関連性が定義されたデータセットである jBATS を提案。
4. どうやって有効だと検証した?
単語の類似度、jBATS を用いたアナロジータスク、感情分析の 3 つの実験を行っている。
実験結果では subcharacter-level な入力より character-level の入力を用いたモデルのほうが良い精度となる場合が多かった。
5. 議論はあるか?
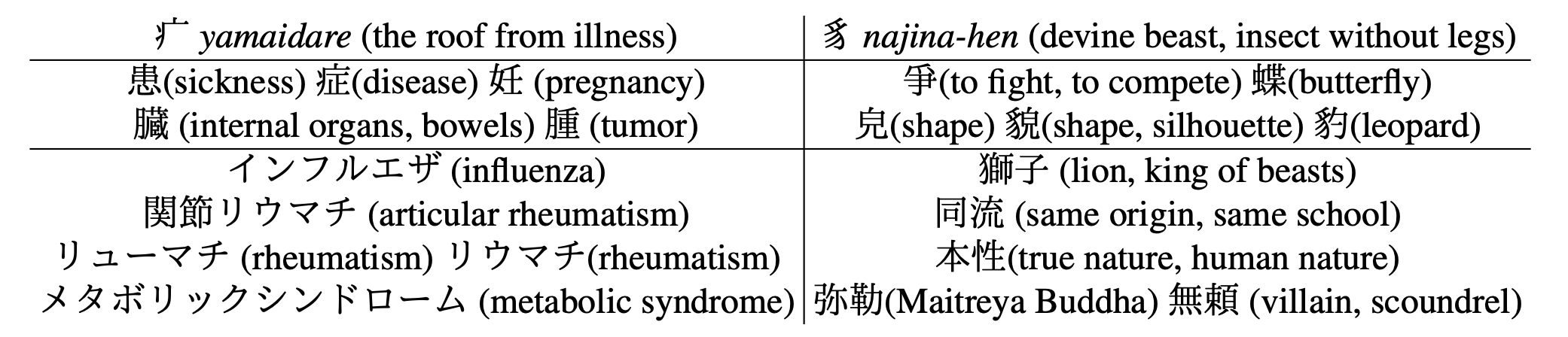
疒(やまいだれ)や豸(なじなへん)に対して近いベクトル表現を得た場合の結果。
やまいだれを持つ症が近い表現になっていることはもちろんのこと、患や腫といった病気に関わる単語が近い表現になっている。
6. 次に読むべき論文はあるか?
- 日本語におけるサブキャラクターを用いた言語モデリングについて
- jBATS について