How Large Vocabulary Does Text Classification Need? A Variational Approach to Vocabulary Selection
1. どんなもの?
精度を保ったまま最小限の語彙を選択する variational vocabulary dropout (VDD) を提案。
2. 先行研究と比べてどこがすごいの?
自然言語処理 (NLP) のタスクに対して deep learning モデルを用いる場合、入力にあらかじめ定義された語彙を元に単語をベクトル化して入力する必要がある。 こうした語彙数は非常に大規模となる場合が多くパラメータ数も増大してしまうため、限られた計算リソース下での実行することは難しい。 したがってタスクを解く精度を保ったまま必要な語彙を選択する必要がある。
本研究ではこの語彙選択問題に対して、タスクを考慮した語彙選択手法である variational vocabulary dropoput (VDD) を提案している。 また適切な語彙選択が行われているかを確認するため、AUC ベースの評価指標を導入し、提案手法の効果を確認している。
3. 技術や手法の”キモ”はどこにある?
語彙選択に対する問題設定
元の embedding と語彙選択を行った後の embedding を使用した場合に、予測精度の差が閾値以上である語彙数を最小にする。
語彙選択に対する評価指標
AUC ベースの評価指標 Vocab@-X%
- X %のパフォーマンス低下が許される場合に必要な最小の語彙数を計算する
- 本研究では
Vocab@-3%およびVocab@-5%を用いている
- 本研究では
Variational Vocabulary Dropout (VDD)
- Bernouli Dropout
- Onehot ベクトルに対してベルヌーイノイズを適用する
-
- しかしながらベルヌーイ分布を reparameterize するのは難しい
-
- Onehot ベクトルに対してベルヌーイノイズを適用する
- Gaussian Relaxation
- ベルヌーイノイズの代わりにガウシアンノイズ を適用する
-
- Reparameterization trick に従うと、 は多変量ガウス分布 を用いて以下のようになる
- Reparameterization trick に従うと、 は多変量ガウス分布 を用いて以下のようになる
-
- ベルヌーイノイズの代わりにガウシアンノイズ を適用する
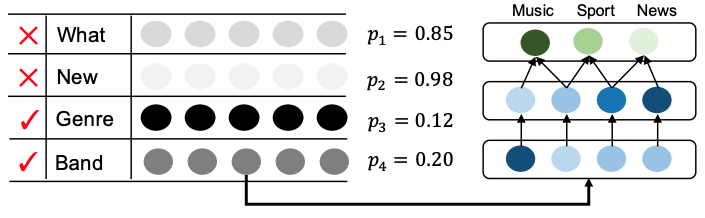
Dropout 率 は 語彙の番目の単語が必要かどうかを示す指標となる。 ここでより数値が大きい場合は番目の語彙をドロップしてもパフォーマンス低下の要因にならないことを意味する。
4. どうやって有効だと検証した?
文書分類 (document classification: DC)、自然言語理解 (natural language understanding: NLU)、自然言語推論 (natural language inference: NLI) のデータセットを用いてそれぞれのタスクにおける VVD の効果を確認している。 提案手法の VVD に対して、ベースラインとして頻度に基づいた語彙形成、TF-IDF に基づいた語彙形成、そして group lasso に基づいた語彙形成を比較している。 各タスクではそれぞれ DC では CNN ベースのモデル、NLU では attetion を導入した bi-directional LSTM モデル、NLI では ESIM モデルを用いている。
すべてのタスクに対して提案手法の語彙選択手法である VVD が outperform する結果となっている。 また語彙選択を考慮した評価指標として Vocab@-X% を用いた場合では、特に提案手法のスコアが良くなっていることが示されており、効果的な語彙選択が行われていることがわかる。
5. 議論はあるか?
学習時の速度について
VVD は確率的な振る舞いを扱うため、テキスト分類に対して学習を行う場合通常の cross entropy よりも時間がかかった。 フルサイズの語彙に対して VVD を適用すると計算時間がかかるため、前段階で精度低下が怒らない程度に語彙を制限したほうがよい。
6. 次に読むべき論文はあるか?
- Deep learning モデルに対するベイジアンベースのモデル圧縮について