Beyond News Contents: The Role of Social Context for Fake News Detection
1. どんなもの?
出版社・ニュース記事・ユーザの 3 つの関係をモデリングすることでフェイクニュース検出の精度向上を目指す TriFN を提案。
2. 先行研究と比べてどこがすごいの?
フェイクニュース検出は主にニュース記事にフォーカスしたものと、ユーザのソーシャルな行動にフォーカスしているものが多い。 これらは偽の情報を判断する言語的な観点やフェイク画像に対する視覚的観点に基づいたモデルの構築を行っている。 またユーザに対して行動ログベースやユーザ間のネットワークベースのモデリングを行っている事例も多い。
本研究では、先行研究では考慮されてこなかった、出版社・ニュース記事・ユーザ行動の 3 つの関係 tri-relationship を考慮することでフェイクニュース検出の精度向上を目指す TriFN を提案している。
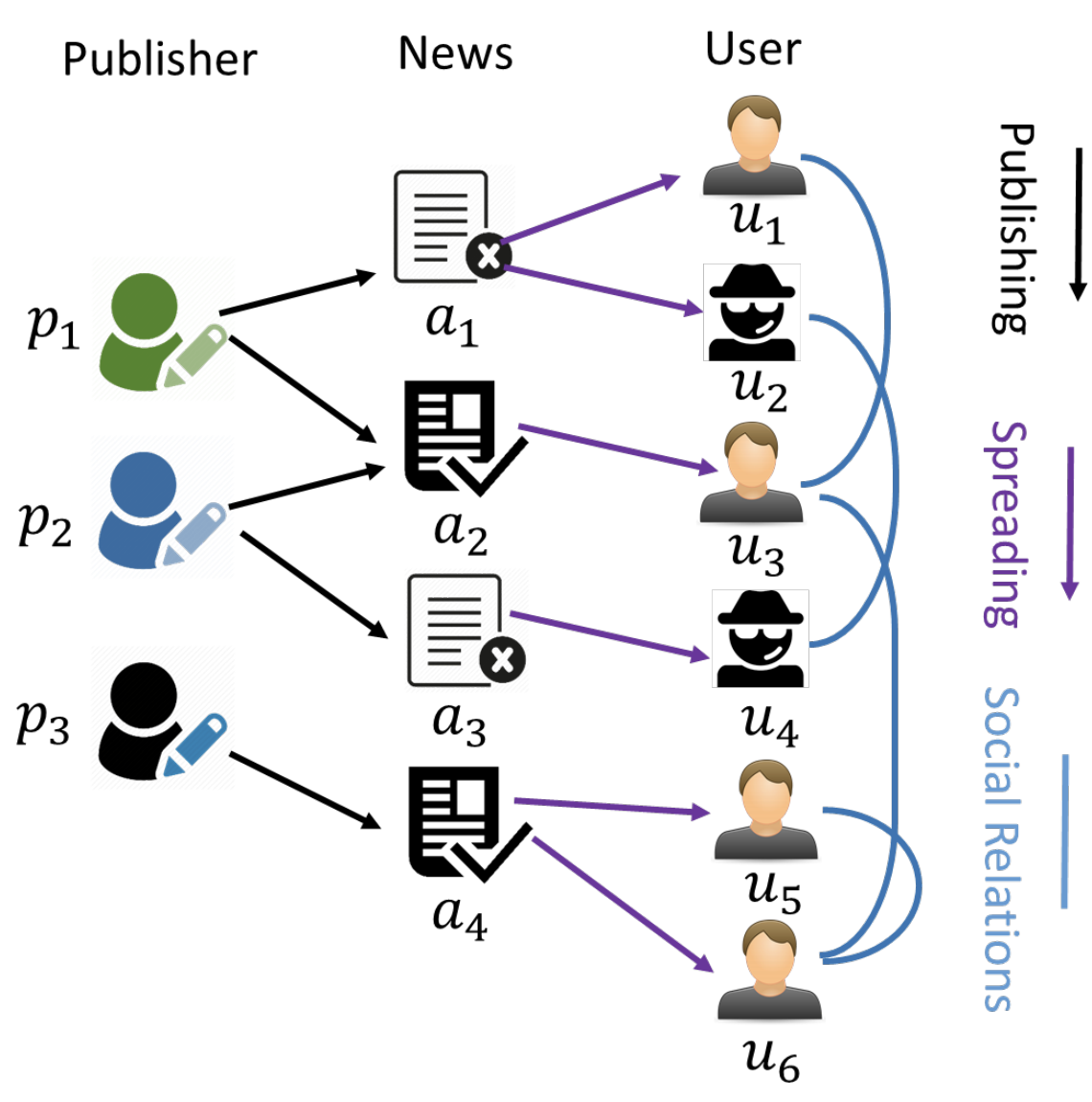
3. 技術や手法の”キモ”はどこにある?
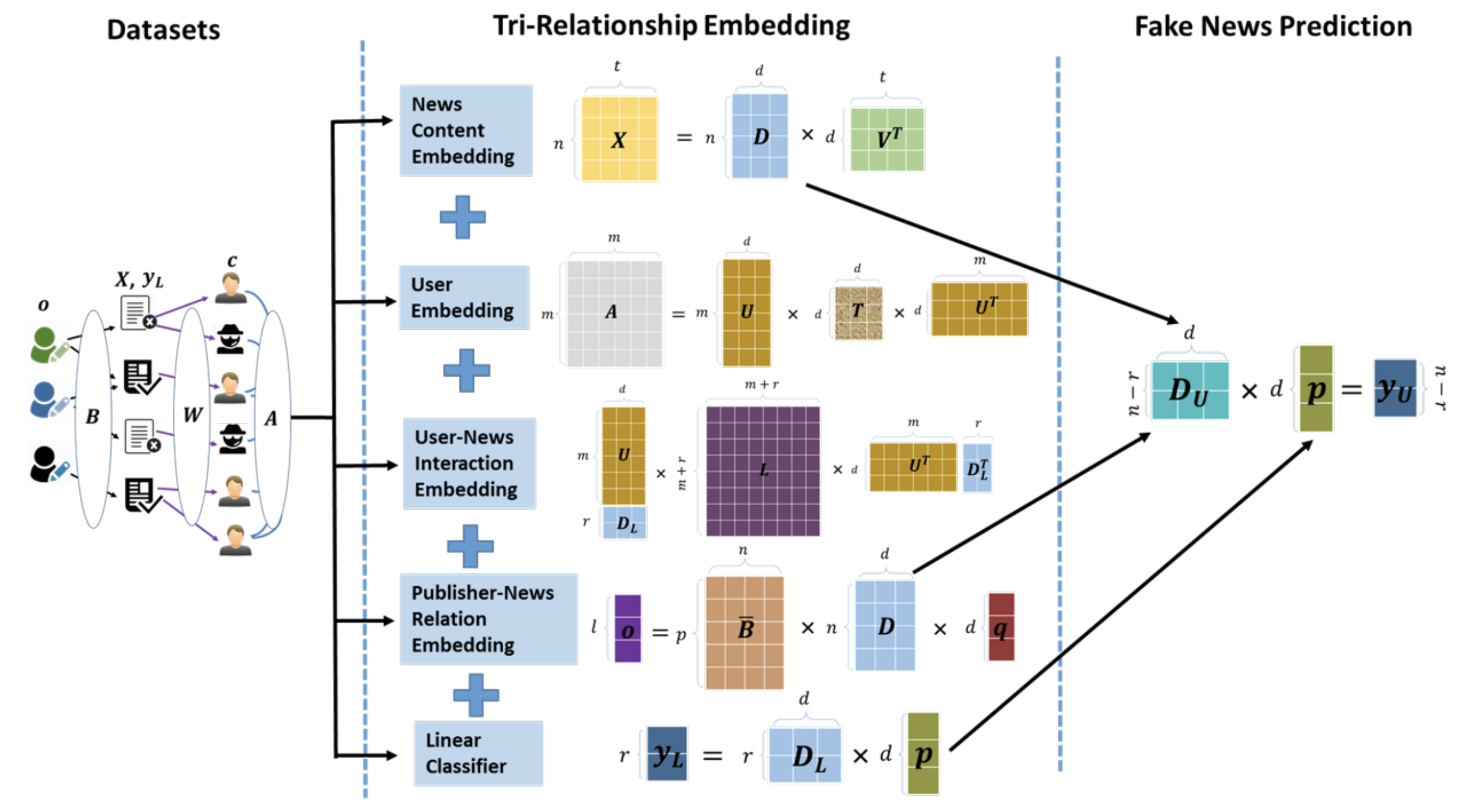
Tri-relationship を考慮したフェイクニュース検出モデル TriFN
TriFN は主に non-negative matrix factorization (NMF) をベースとした 5 つのコンポーネントから構成される。
- News Contents Embedding
- Bag-of-words 表現なニュース記事から NMF でニュース記事の潜在表現を学習する
- User Embedding
- ユーザのソーシャルな関係から NMF でユーザの潜在表現を学習する
- User-News Interaction Embedding
- ユーザの信頼度によって得られるニュース記事の潜在表現を学習する
- Publisher-News Relation Embedding
- 出版社の党派的なバイアスを考慮したニュース記事の潜在表現を学習する
- Semi-supervised Linear Classifier
- ニュース記事に対してフェイクニュース予測を行うための学習器を学習する
- 半教師あり学習の枠組みを同時に使用し、ラベルが付与されていないデータからも学習する
4. どうやって有効だと検証した?
FakeNewsNet データセットを用いて、trueかfakeかの 2 値分類問題としてフェイクニュース検出に対する検出精度の比較を行っている。
比較対象として先行研究で提案されている複数の特徴抽出手法 (RST, LIWC, Castillo とこれらを組み合わせた RST + Castillo, LIWC + Castillo) とベースラインのモデル (LogReg, NBayes, DTree, RForest, XGBoost, AdaBoost, Gradient Boosting) で比較している。
5. 議論はあるか?
- 早期のフェイクニュース検出におけるパフォーマンス
- 記事公開から 12 時間後 〜 96 時間後の各時間におけるフェイクニュース検出の精度比較を行った結果、提案手法の TriFN が一番良かった。
- モデルのパラメータ分析
- ユーザのソーシャルな関係の寄与をコントロールするパラメータを大きくすると精度が向上した。
- ユーザとニュース間の関係よりユーザのソーシャルな関係のほうが予測に寄与する。
- ユーザのソーシャルな関係の寄与をコントロールするパラメータを大きくすると精度が向上した。
6. 次に読むべき論文はあるか?
- フェイクニュース検出における data augmentation