Joint Embedding of Words and Labels for Text Classification
1. どんなもの?
テキスト分類の際に教師ラベルのembeddingと単語のembeddingを組み合わせたattentionの枠組みを用いる、Label-Embedding Attentive Model (LEAM) を提案。
2. 先行研究と比べてどこがすごいの?
画像認識分野および自然言語処理分野において、label embeddingを用いたさまざまな枠組みが提案されてきた。近年の自然言語処理分野では単語embeddingやattentionを用いることで、テキスト分類等のタスクの精度向上が示されてきた。 本研究では効果的なattentionモデル構築のためにlabel embeddingを学習する、LEAMを提案している。
3. 技術や手法の”キモ”はどこにある?
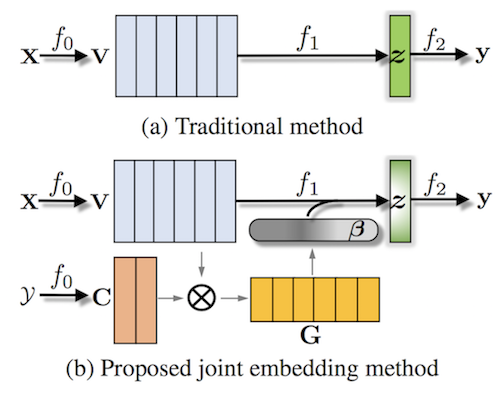
- 単語embedding と label embedding から
compatibilityを計算 - softmaxを用いて をnormalizeしたattention を計算
- 単語embeddingとattentionの重み付け平均を計算したdocument embedding を用いてテキスト分類を行う
- テスト時にはlabel embedding において、すべてのクラスのembeddingを利用する
4. どうやって有効だと検証した?
AGNews、Yelp Review Full、Yelp Review Polarity、DBPedia、Yahoo! Answers Topicの5つのデータセットを用いている。 ベースラインのモデルとしてBag-of-words、Shallow/Large word CNN、LSTM、SA-LSTM、Deep CNN、SWEM、fastText、HAN、Bi-BloSANとテキスト分類の精度を比較している。
上記に加えて医療テキストデータセットであるMIMIC-IIIを用いた実践的な評価を行っている。
5. 議論はあるか?
- モデルのパラメータ数と学習時間について
- SWEMに次いで少ないパラメータ数と学習時間を実現している
- label embeddingの有効性について
- 学習から得られたlabel embeddingとdocument embeddingをt-SNEで可視化すると、クラスに対応するlabel embeddingとdocument embeddingに強い相関が見られた

- 学習から得られたlabel embeddingとdocument embeddingをt-SNEで可視化すると、クラスに対応するlabel embeddingとdocument embeddingに強い相関が見られた
- 医療テキストに対する有効性について
- attentionを可視化すると、医療に関連する語がハイライトされていることが示されている。

- attentionを可視化すると、医療に関連する語がハイライトされていることが示されている。
6. 次に読むべき論文はあるか?
- 画像認識分野におけるlabel embedding
- 画像分類
- マルチモーダル
- Frome, Andrea, et al. “Devise: A deep visual-semantic embedding model.” Advances in neural information processing systems. 2013.
- Kiros, Ryan, Ruslan Salakhutdinov, and Richard S. Zemel. “Unifying visual-semantic embeddings with multimodal neural language models.” arXiv preprint arXiv:1411.2539 (2014).
- 画像中のテキスト認識
- Zero-shot learning
- Palatucci, Mark, et al. “Zero-shot learning with semantic output codes.” Advances in neural information processing systems. 2009.
- Yogatama, Dani, Daniel Gillick, and Nevena Lazic. “Embedding methods for fine grained entity type classification.” Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 2: Short Papers). Vol. 2. 2015.
- Ma, Yukun, Erik Cambria, and Sa Gao. “Label embedding for zero-shot fine-grained named entity typing.” Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers. 2016.
- 自然言語処理におけるlabel embedding
- Heterogeneous networkによるlabel embedding
- マルチタスク学習
- ベースラインのモデルについて
- Bag-of-words、Shallow/Large word CNN、LSTM
- SA-LSTM
- Deep CNN
- SWEM
- HAN
- Bi-BloSAN