Learn to Pay Attention
1. どんなもの?
画像認識に対して学習可能なattention機構をCNNに導入し、baseline手法を超える精度を実現
2. 先行研究と比べてどこがすごいの?
Convolutional Neural Network (CNN) は画像処理分野で素晴らしい結果を残しているが、こうした問題に対してモデルが推論する過程が不透明であり、結果の考察が難しい。 そこで先行研究ではモデルの解釈性の向上のために、推論する画像のどの部分に注目しているかを可視化する手法が複数提案されている。 しかしながらこれらの手法は学習済みのモデルに対してのみ適用可能という制限がある。
Attention機構は学習時に入力のどの部分に注視するかを学習することが可能であり、機械翻訳や画像に対する説明文自動生成(キャプショニング)、VQAなどにおいて精度向上に寄与している。
Attentionを計算する場合にクエリが必要な画像キャプションやVQAに対して、本研究ではattentionを推定するためにglobalな画像表現を利用し、分類問題においてもattention機構を導入することに成功している。
3. 技術や手法の”キモ”はどこにある?
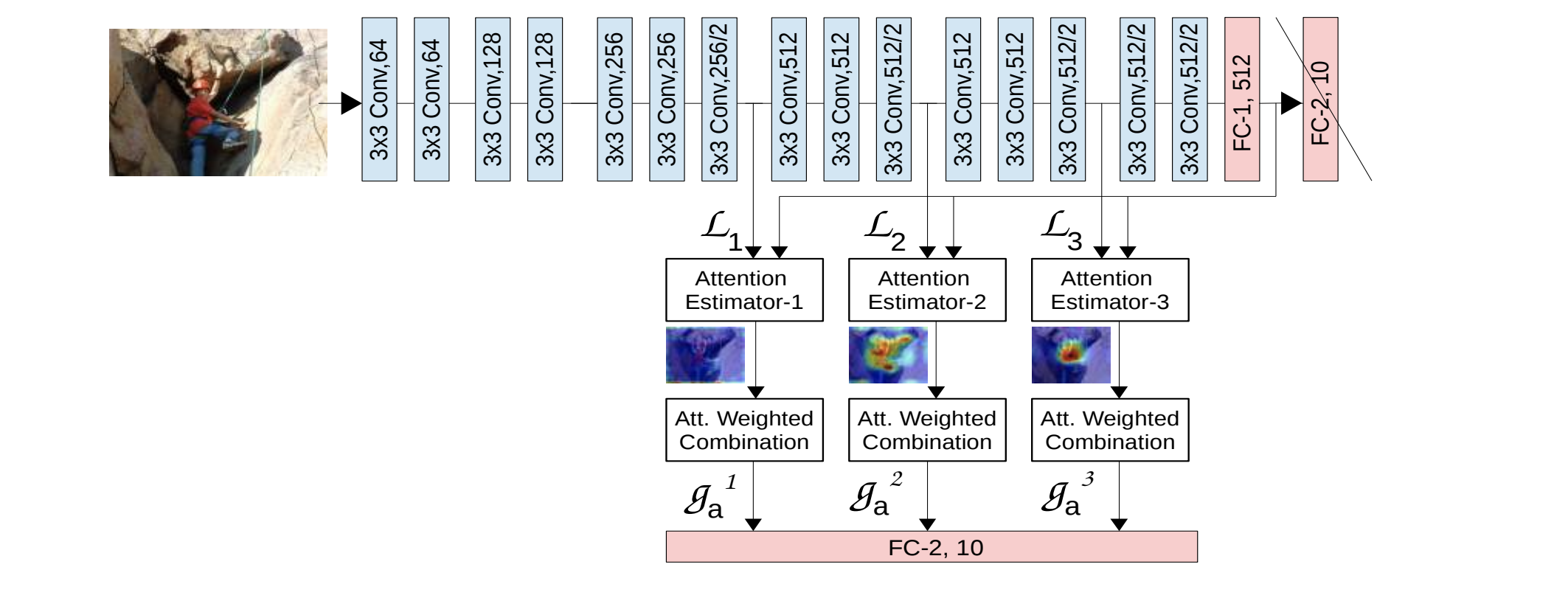
local feature vector と global feature vector を用いたattention機構を実現した。
- 畳み込み層から活性化関数を通して得られるlocal feature vector と最終全結合層の出力であるglobal feature vector から、
compatibility scoreを計算し、各local feature vectorの重要度 (attention) を算出する - 重要度 とlocal feature vectorとの重み付き平均 を計算する
- 各畳み込み層から得られる複数の をconcatしたベクトルを用いて分類を行う
compatibility socreを計算する際に用いる は ドット積 を利用した
4. どうやって有効だと検証した?
ベースラインとして、先行研究のVGG-GAPおよびVGG-PAN、ResNet164と、VGG/ResNetに対して本研究のattention機構を導入できるようパラメータを調整したネットワークを比較している。
global feature vectorとlocal feature vectorに対してcompatibility scoreを計算する際にドット積を用いたdpと、パラメータを用いたpcを比較している。
評価に用いるデータセットはCIFAR10/100、CUB-200-2011、SVHN等を利用している。また導入したattention機構がadversarialなサンプルに対してもロバストであることを示す実験も行っている。
5. 議論はあるか?

提案手法 (proposed) と既存手法 (existing) それぞれのattention mapを可視化した結果である。提案手法がよりdiscriminativeな形で物体を認識していることが示されている。

CUB-200データセットで学習した提案手法の結果である。10層目は目の特徴を捉えており、13層目は体全体を捉えていることが示されている。
6. 次に読むべき論文はあるか?
- モデルの解釈性向上のための可視化手法
- Simonyan, Karen, Andrea Vedaldi, and Andrew Zisserman. “Deep inside convolutional networks: Visualising image classification models and saliency maps.” arXiv preprint arXiv:1312.6034 (2013).
- Cao, Chunshui, et al. “Look and think twice: Capturing top-down visual attention with feedback convolutional neural networks.” Proceedings of the IEEE International Conference on Computer Vision. 2015.
- Global average pooling (GAP)
- Attention機構が用いられている先行研究
- 属性予測 (Progressive Attention Networks (PAN))
- 機械翻訳
- 画像に対する説明文自動生成
- Xu, Kelvin, et al. “Show, attend and tell: Neural image caption generation with visual attention.” International Conference on Machine Learning. 2015.
- You, Quanzeng, et al. “Image captioning with semantic attention.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016.
- Mun, Jonghwan, Minsu Cho, and Bohyung Han. “Text-Guided Attention Model for Image Captioning.” AAAI. 2017.
- Visual question answering (VQA)
- Xu, Huijuan, and Kate Saenko. “Ask, attend and answer: Exploring question-guided spatial attention for visual question answering.” European Conference on Computer Vision. Springer, Cham, 2016.
- Yang, Zichao, et al. “Stacked attention networks for image question answering.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016.