Natural Language Processing (almost) from Scratch
1. どんなもの?
自然言語処理の様々なタスクに対してタスク依存しないようなロバストな特徴を、ニューラルネットワーク(NN)をベースとしたアーキテクチャで学習する。
2. 先行研究と比べてどこがすごいの?
自然言語処理の主なタスクとして、品詞タグ付け(Part-of-Speech Tagging)・チャンキング(Chunking)・固有表現抽出(Named Entity Recognition)・意味役割付与(Semantic Role Labeling)などがある。従来これらのタスクを解くにはタスク依存の特徴量選択が熟練者の手で行われてきた。こうして得られた特徴量を元に、複数のモデル(SVMやRandom Forestなど)で構成されたシステムで予測を行ってきた。
本研究ではタスクに依存しないような特徴量を自動で獲得するようなNNのアーキテクチャを提案し、自然言語処理の複数タスクに適用している。
3. 技術や手法の”キモ”はどこにある?
3.1. 教師あり学習
-
入力される単語をLookup TableでEmbedding
- 単語Embeddingから高次の特徴を抽出する2つのアプローチ
- Windowアプローチ
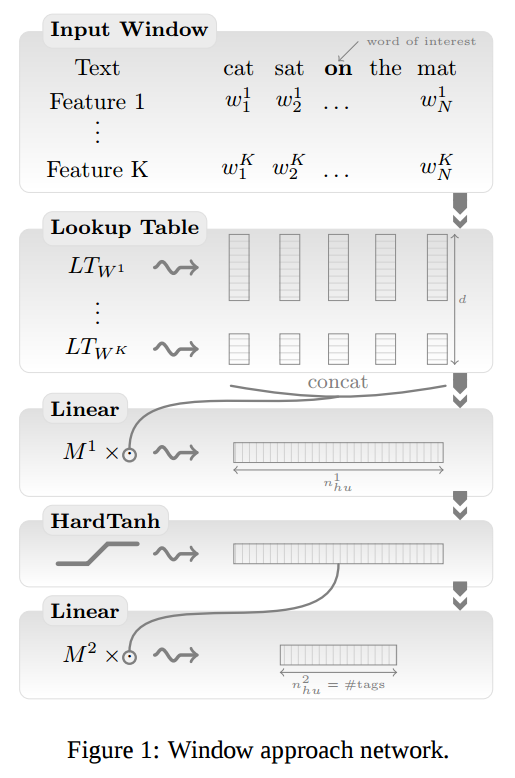
- Sentenceアプローチ
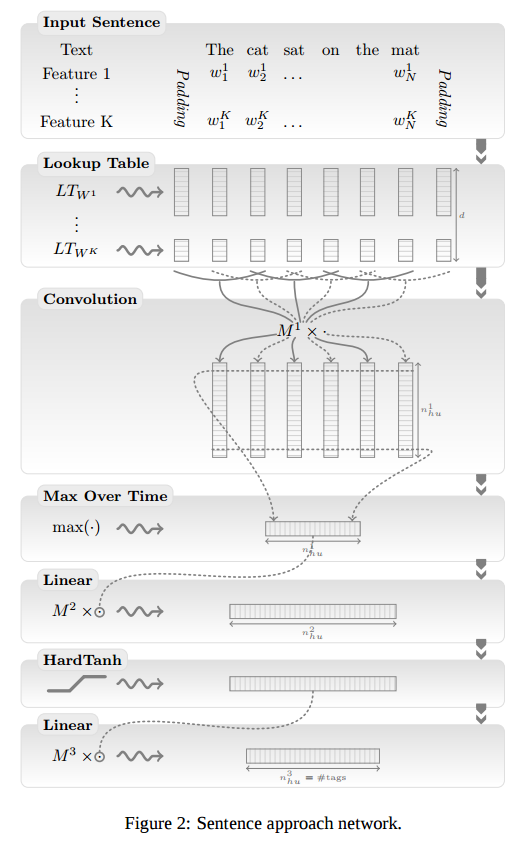
- Windowアプローチ
- ネットワークの最終層でタグの予測を行う
- 各タスクで可能性のあるすべてのタグについてスコアを計算する。
- 計算したスコアを尤度とし評価する。
- 他の単語に対するネットワークの出力値も考慮するため、単純なクロスエントロピー誤差関数は用いていない
- 単語レベルの対数尤度
- 文レベルの対数尤度
- 小文字のみの単語と大文字小文字情報を入力している
- 数字については”NUMBER”という文字列に置き換えている
3.2. 半教師あり学習
教師あり学習のみで学習したモデルのEmbeddingを観察すると、意味的に似ていない単語が近い意味の単語として分類されていることが分かった。また前述の手法を組み合わせた教師あり学習のみのモデルでは、ベンチマークの結果を上回ることができなかった。
結果を向上させるため、ラベルの無いデータから言語モデルをトレーニングし、得られたパラメータを用いてNNの初期化した後、教師あり学習させている。
結果があまり良くなかったのは、データの数が少ないことによる未学習が原因だと考えられる。今回は英語の全WikipediaコーパスとReuters RCV1コーパスを用いて言語モデルをトレーニングしている。
半教師あり学習を導入した後に学習したEmbeddingを観察すると、意味的に似ている単語が近い意味の単語として分類されている。
3.3. マルチタスク学習
半教師あり学習を導入したことで、よりベンチマークのトップスコアに近づくことができた。今度はマルチタスク学習を導入し、効果が上がっている。
マルチタスクアプローチはモデル間のパラメータを共有しながら学習を行う方法である。

3.4. タスク依存の特徴量選択
ここまでではタスク依存しないような特徴量を用いてトップスコアに肉薄するベンチマークスコアを出してきた。最後にタスク依存の特徴量を提案手法のモデルに入力し、効果を見ている。
- Suffix Features
- Gazetteers
- Cascading
- Ensembles
- Parsing
- Word Representations
4. どうやって有効だと検証した?
以下のデータセットを用いて各タスクに対する提案手法の単語あたりの正解率やF1スコアを比較し、評価を行っている。
| タスク | データセット |
|---|---|
| 品詞タグ付け | Wall Street Journal |
| チャンキング | Wall Street Journal |
| 固有表現抽出 | Reuters |
| 意味役割付与 | Wall Street Journal |
教師あり学習のみの結果ではベンチマークのトップスコアに届いておらず、半教師あり学習の導入でほぼ同スコアになっている。マルチタスク学習や提案モデルにタスク依存の特徴量を入力した場合、トップスコアを超えるパフォーマンスを出した。
5. 議論はあるか?
- 殆どのタスクに対してWindowアプローチは有効であったが、意味役割付与タスクについては結果があまり良くなかった。これは単語のタグが動詞に依存しているため、windowの外に動詞あると正確にタグを予測できないことがあった。これを改善したのが畳み込み層のあるSentenceアプローチである。