Effective Use of Word Order for Text Categorization with Convolutional Neural Networks
1. どんなもの?
高次元のone-hotベクトルをConvolutional Neural Network(CNN)に入力し、語順を考慮した文書分類を行う。
2. 先行研究と比べてどこがすごいの?
従来の文書分類のアプローチとして、文書をBag-of-Wordsベクトルで表現し、SVMなどのモデルを用いて分類することが多い。しかしながらBag-of-Wordsは現れる語の順序を考慮しないベクトルとなっている。自然言語処理の評判分析といったタスクでは、語の順番を考慮しない場合は高いパフォーマンスを出すことができない。
従来CNNには入力としてWord Embeddingを用いる場合があるが、本研究では高次元のone-hotベクトルを入力することで、小さなテキスト領域のEmbeddingを学習している。
3. 技術や手法の”キモ”はどこにある?
- 文書を2つのベクトル表現にして入力し、比較
- seq-CNN
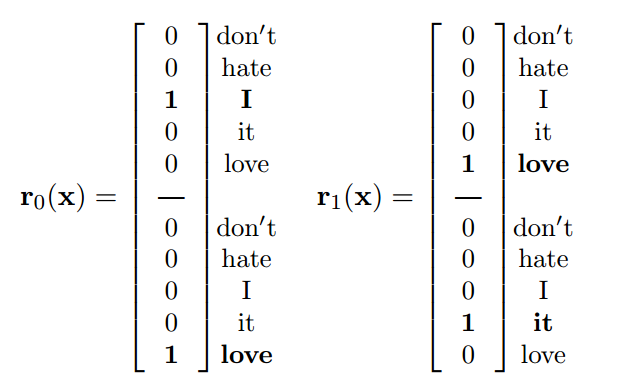
- bow-CNN
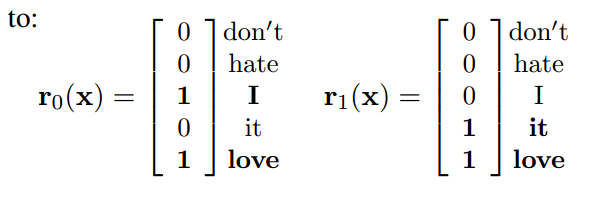
- seq-CNN
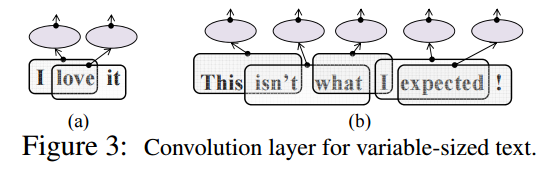
- 可変長である文書ベクトルに対応したPooling層
- Parallel CNN
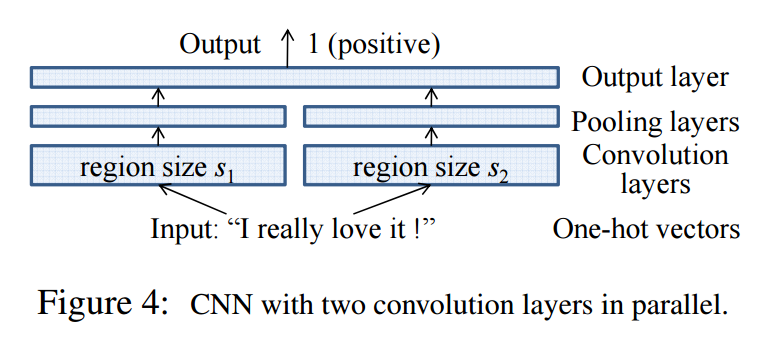
4. どうやって有効だと検証した?
評判分析用のIMDB movie reviewの映画レビューデータセットとElectronics product reviewsのエレクトロニクス製品のレビューデータセット、トピック分類用のRCV1のニュース記事データセットを用いて評価を行っている。IMDBとElectronics product reviewsにおいてはseq-CNNが、RCV1においてはbow-CNNが従来手法より遥かに高いパフォーマンスを出している。
5. 議論はあるか?
- IMDB・Elecでseq-CNNがbow-CNNよりもよい結果を出した。これは短い文でとても強い感情が移入されている(たとえば「とてもよい映画だ!」のような)文においては、語順が考慮されるseq-CNNモデルが評判分析タスクで高いパフォーマンスを出していると考えられる。
- 反対にRCV1ではbow-CNNがseq-CNNよりもより結果を出した。これはトピック分類においては小さいテキスト領域よりも大きいテキスト領域の内容がより効果的であるからだと考えられている。