Dependency-based Convolutional Neural Networks for Sentence Embedding
1. どんなもの?
単語と単語の親子関係から木構造を構築し、それらの影響を考慮したDependency-based Convolutional Neural Network(DCNN)を提案している。
2. 先行研究と比べてどこがすごいの?
先行研究ではword2vecでベクトル化した文をシンプルなアーキテクチャのCNNに入力し、学習を行っている。このモデルでは感情分析や文書分類などのタスクにおいて優れたパフォーマンスを出している。しかしながら先行研究のモデルではn-gramのような直近の語の関係のみが捉えられているだけで、長距離の語の関係を捉えることができていない。
本研究では長距離依存の係り受け関係を捉えるために予め構文解析を行い、それらの情報をCNNに入力することで、より文の意味を捉えるような構造になっている。

3. 技術や手法の”キモ”はどこにある?
-
ancestor pathsとsiblingsの情報を単語情報に付加
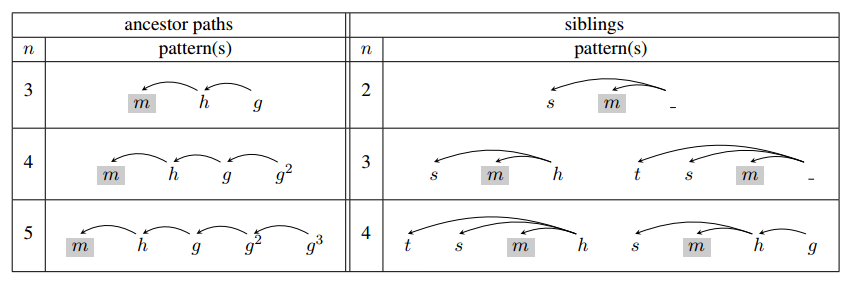
- Max-Over-Tree Pooling(Max poolingのParse Tree版)
- Dropout
- 依存関係のパースにはStanford parserを用いている
- ancestor・siblings・sequentialの3つのモデルを組み合わせるとパフォーマンスが安定する
4. どうやって有効だと検証した?
感情分析データセットであるMovie Review(MR)とStanford Sentiment Treebank(SST-1)、質問分類データセットであるTRECを用いて評価を行っている。MRはpositive、negativeのラベルが付与されており、SST-1はより粒度の細かいvery positive、positive、neutral、negative。very negativeのラベルが付与されている。TRECは6つのカテゴリに従っている。またサブカテゴリに分けたTREC-2を用いて検証している。
先行研究のCNNアーキテクチャやRecursive NN、Recurrent NN、従来手法のSVMなどと提案手法を比較している。MR、TRECでは提案手法のモデルがstate-of-the-artな結果となっている。またSST-1においてもベストスコアに近い良い結果となっている。TREC-2では従来手法のSVMモデルに負けている。しかしながらこのモデルは人間の手が加えられた60のルールにしたがった特徴量を用いているので、自動的に特徴量を学習する提案手法のほうがより一般的なものと言える。
5. 議論はあるか?
- TRECデータセットにおいて、DCNNが分類に失敗してベースラインCNNが成功している例と、ベースラインCNNが分類に失敗してDCNNが成功している例。そもそも構文パーサーが間違ってしまうこともある。またDCNNが長距離の依存関係を捉えられていることがわかる。

6. 次に読むべき論文はあるか?
ベースラインであるCNN