ImageNet Classification with Deep Convolutional Neural Networks
1. どんなもの?
ImageNetデータセットについてDeepなConvolutional Neural Network(CNN)をトレーニングし、今までに報告されていた最高精度を達成した。
2. 先行研究と比べてどこがすごいの?
ImageNetデータセットでは22000カテゴリ、全1500万枚の高画質の画像が収録されている。このような大規模なデータセットに対して従来の機械学習手法を適用するのは困難だと考えられている。特に従来の機械学習手法はデータに対して最適な特徴量を選択する必要があるが、大規模で複雑なデータから普遍的な特徴量を選択するのは難しい。
本研究ではCNNを用いて自動的に最適な特徴量を抽出することができる。またCNNのアーキテクチャをより深いネットワークとすることでモデルの表現能力を上げ、様々なデータに対して適応させていくことができている。
GPUの発展により効率的にモデルの学習を行うことができる。特に2次元の畳み込み操作がGPUで最適化されているため、とても大きなデータセットに対しても少ない計算時間で結果を出すことができる。
3. 技術や手法の”キモ”はどこにある?
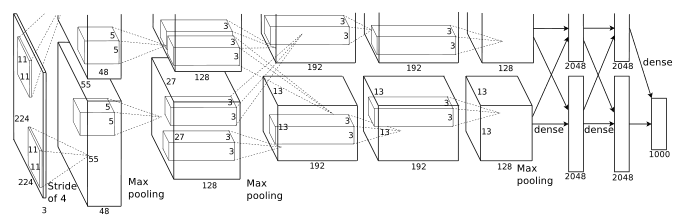
- 畳み込み層5層、全結合層3層の計8層のCNN
- 活性化関数にReLUを使用することで、学習の収束を早めることができた
- モデルを複数GPUでトレーニングを行う
- Local Response Normalization(局所的応答正規化)
- Max Pooling
- 過学習を防ぐテクニック
- Data Augmentation
- 256x256の画像からランダムに224x224サイズにクロップ
- 水平方向にフリップした画像を生成
- PCAを用いたColor Augmentation
- Dropout
いくつかの隠れ層を確率的にドロップさせることで、特定のニューロンに依存せず汎化性能が上がる
- Data Augmentation
- バッチサイズ128でSGDを使用
- Momentumは0.9
- Weight Decayは0.0005
- 各層のパラメータの初期化方法
- 各層の重みは平均0標準偏差0.01のガウス分布に従って初期化
- 2・4・5層目畳み込み層と全結合層のバイアスは1で初期化
- その他の層のバイアスは0で初期化
4. どうやって有効だと検証した?
ImageNet Large-Scale Visual Recognition Challenge(ILSVRC)という1000カテゴリの画像が含まれているデータセットを使用してtop-1 error rateとtop-5 error rateの2つのエラー率を報告している。top-5 error rateはモデルによって算出された最も可能性が高いと考えられる5つのラベルのうち、正しいラベルが含まれていない割合である。
ベストな結果であった従来のSparse codingやSIFT特徴量を用いたFisher Vectorを提案手法が遥かに凌駕するパフォーマンスを出していることがわかる。
5. 議論はあるか?
- 教師なしのプレトレーニングは行っていないが、十分な計算資源があれば有効であると示唆されている。
- このネットワーク構造はのちに筆頭著者のAlex Krizhevskyの名前をとって「AlexNet」と呼ばれている。