Neural Machine Translation using Bitmap Fonts
1. どんなもの?
ビットマップフォントにした漢字や単語を入力として、中国語からスペイン語に変換する翻訳システムを提案する。
2. 先行研究と比べてどこがすごいの?
Deep Learningにおける文章の翻訳はAutoencoder構造を主に使用している。通常、入力されるセンテンスの各々の単語を1-of-K表現で表しモデルに入力をする。
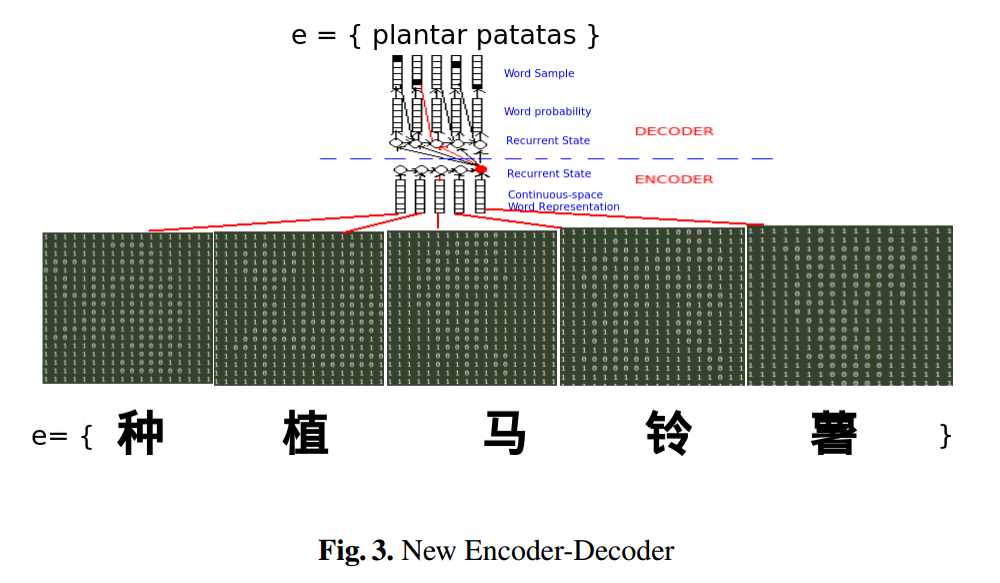
本研究では、アルファベット1文字に比べてより情報量が多い中国語1文字をビットマップ画像化することで、より多くの情報を翻訳システムに供給できるのではないかと考えられている。
3. 技術や手法の”キモ”はどこにある?
- AttentionをベースとしたEncoder-Decoderモデルを利用している
- 入力は中国語の文字をを2次元のビットマップ画像に変換したものを使っている
4. どうやって有効だと検証した?
中国語-スペイン語のコーパスであるUnited Nations Corpus(UN)を用いて評価を行っている。文字レベルの分かち書き・単語レベルの分かち書きに通常の1-of-K表現とビットマップ画像表現を入力として初期化した場合、単語レベル分かち書き+ビットマップ表現がBLEUスコアが一番良い結果となっている。
5. 議論はあるか?
本研究の結果はState-of-the-Ariな結果程遠いものとなっている。これは比較的小規模なデータセットを使用していることが原因だと考えられている。しかしながら本研究は標準的な単語レベルのベクトルよりもビットマップ画像を用いた初期化を利用することで、より効果的に情報を利用することができている。
6. 次に読むべき論文はあるか?
ベースラインの翻訳モデルについて。