Learning Character-level Compositionality with Visual Features
1. どんなもの?
中国語や日本語、韓国語の文字画像情報から埋め込み表現を獲得し、文書分類に利用する。
2. 先行研究と比べてどこがすごいの?
近年の自然言語処理においては、単語レベルや文字レベルの特徴を利用してタスクを解く先行研究がある。
本研究ではConvolutional Neural Network(CNN)で文字画像から視覚的な特徴を取り出し、その特徴を用いてRecurrent Neural Network(RNN)で文書分類を行うものとなっている。本研究のモデルの特性上、視覚的に似ている文字は似たembeddingを獲得するため、先行研究で結果を出している文字単位モデルと同様に、低頻度語や未知語に対して効果的に処理を行うことができる。
3. 技術や手法の”キモ”はどこにある?
- CNNとRNNを用いた構造
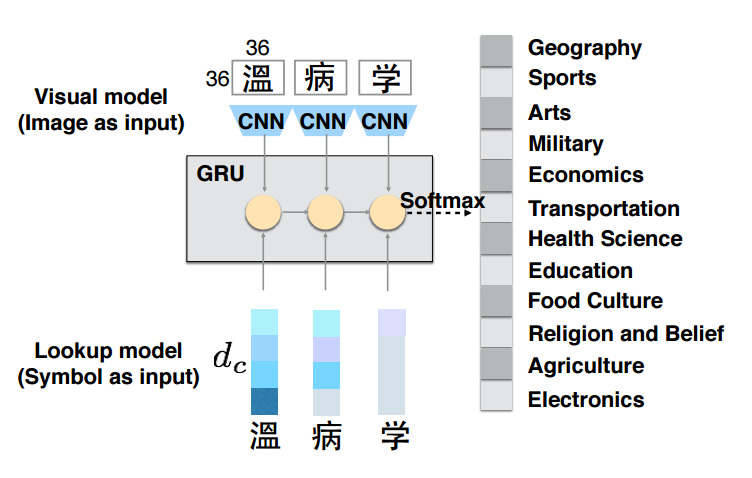
- 複数の角度からのembedding
- VISUAL model
- CNNを用いた文字画像からの視覚的な特徴を捉えたembedding
- LOOKUP model
- 互いの文字の意味を捉えた文字単位embedding
- VISUAL model
- RNNエンコーダーとしてGated Recurrent Unit(GRU)を使用
- 複数embeddingのアンサンブル (Fusion-based Models)
- Early Fusion
- RNNに連結した2つのembedding(VISUAL & LOOKUP)を入力する
- Late Fusion
- VISUAL・LOOKUPそれぞれのembeddingで予測を行い、softmaxの出力結果を平均する
- Fallback Fusion
- ある閾値よりも現れる頻度が少ない文字が含まれるものに対してVISUAL modelで予測を行い、それ以外をLOOKUP modelで予測する
- Early Fusion
4. どうやって有効だと検証した?
中国語・日本語・韓国語のWikipediaから収集した記事タイトルについて、12クラスのタイトル分類を行っている。ベースラインをLOOKUP modelとし、提案手法のVISUAL modelと比較を行っている。
結果はLOOKUP modelがVISUAL modelを1~2%程度上回るものとなっている。これはLOOKUP modelが高頻度文字から直接意味を捉えるようなembeddingを学習した結果と言える。
提案手法は文字画像情報から視覚的に似ている文字が近いembeddingとなるように学習されるため、低頻度文字に強い。この効果を検証するため、低頻度文字トップ100が含まれるデータに対して予測を行ったところ、VISUAL modelがLOOKUP modelよりも優れた結果を出している。
5. 議論はあるか?
- 学習時間はCNNを挟むVISUAL modelのほうがLOOKUP modelよりも30倍程度遅いが、テスト時間は同程度である。
- トレーニングデータ全体の50%・12.5%としたときにVISUAL modelのほうがよりスコアが高かった。
- LOOKUP modelよりもVISUAL modelのほうがよりロバストである。
- Traditional Chinese(繁体字)でトレーニングしたVISUAL modelでSimplified Chinese(簡体字)のテストデータで予測を行っても良い結果を出している。
- 繁体字も簡体字も視覚的に似ている文字であり、モデルが類似の文字間でも適応が可能であると考えられる。
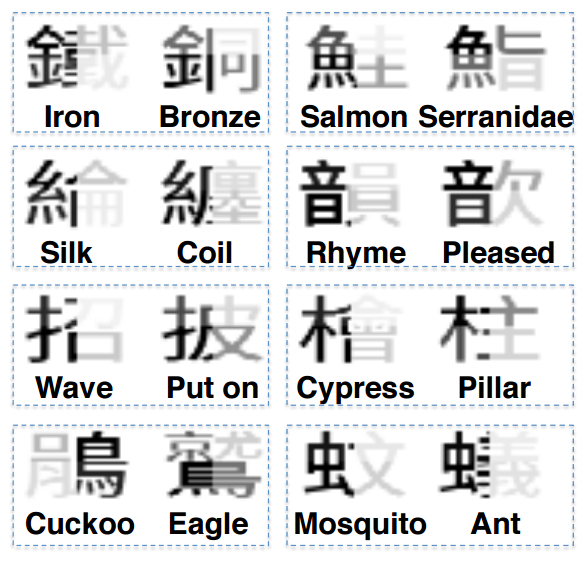
- 文字のどの部分が寄与しているかを可視化した結果が以下のようになっている。
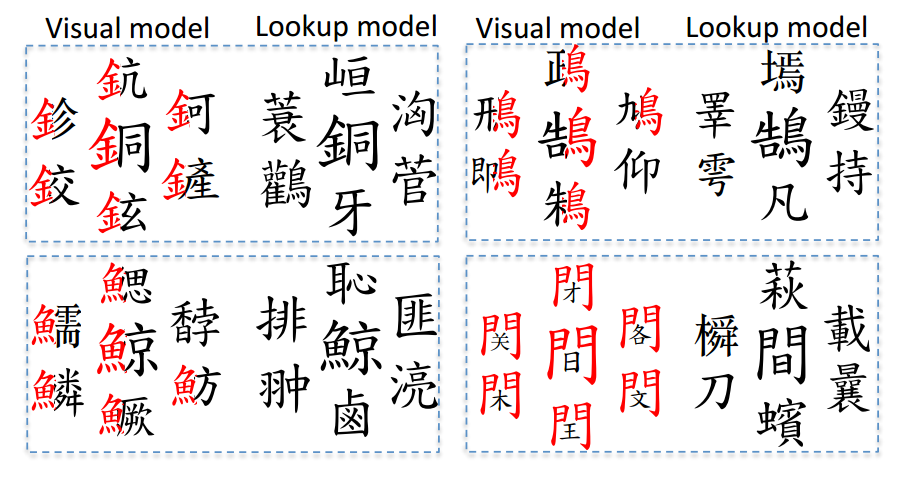
- 学習した文字embeddingについてK-nearest neighborsを用いて近傍6つのembeddingを図示した結果が以下のようになっている。
6. 次に読むべき論文はあるか?
本研究のモデルは以下にインスパイアされている。
GRUについて
文字のどの部分が寄与しているかを可視化する際の参考
文字レベルのCNNで文書分類を行っている先行研究