Grad-CAM: Why did you say that? Visual Explanations from Deep Networks via Gradient-based Localization
1. どんなもの?
Convolutional Neural Network(CNN)の予測結果を視覚的に説明する,Gradient-weighted Class Activation Mapping(Grad-CAM)を提案.
2. 先行研究と比べてどこがすごいの?
CNNを始めとしたDeep modelを使う場合,抽象度の高い学習により予測結果の解釈が難しくなる.信頼できる知的システムを構築するためには,システムが「なぜそのように判断したのか」を解釈できるような透過的なモデルでなければならない.
先行研究ではCNNの予測結果に対してGuided BackpropやDeconvolutionなどを用いて.重要な領域をハイライトをするモデルが提案されている.これらは高解像度でクラスを予測できるがモデル全体の可視化を行うものであり,特定の入力画像に対する予測の可視化を行っていない.
Class Activation Mapping(CAM)という手法があるが,これは分類に用いられたモデルアーキテクチャに手を加えることで,入力画像に対する予測の可視化を行っているものである.しかしながらこの手法は画像分類タスクで正解率が低くなってしまったり,画像のキャプション生成や画像に対する質問応答といったタスクには適していない.

本研究では入力画像に対してCNNモデルがどの領域に注目しているかを可視化できるGrad-CAMを提案している.CAMのようにモデルのアーキテクチャを変えること無く,どのようなCNNにも適用でき,画像キャプション生成や画像に対する質問応答タスクにも応用可能である.
3. 技術や手法の”キモ”はどこにある?
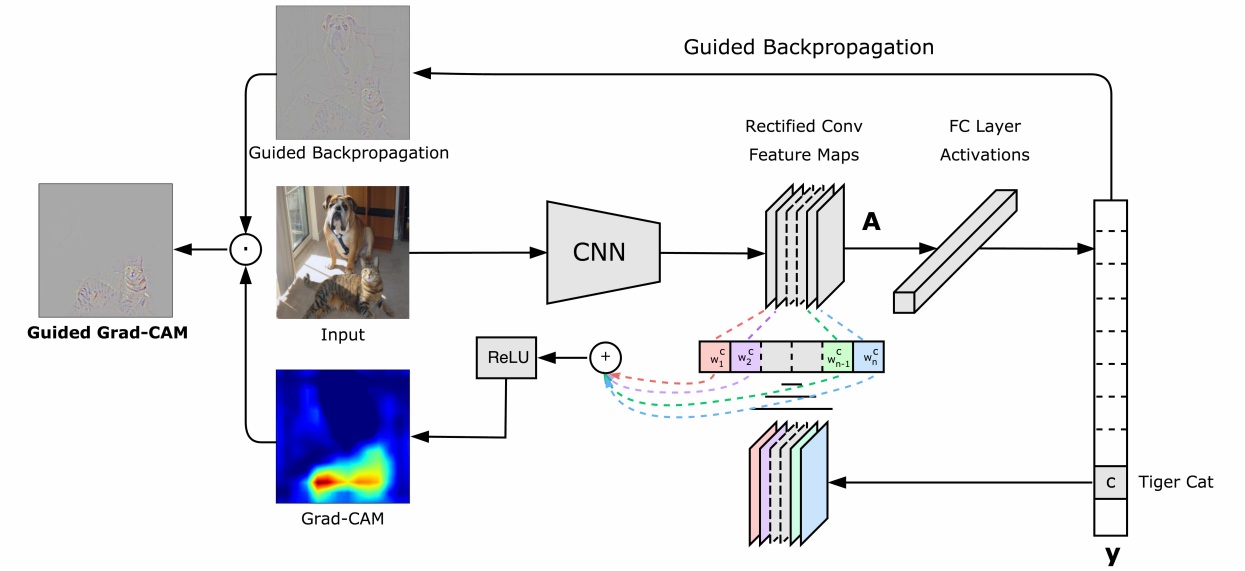
- Gradient-weighted Class Activation Mapping(Grad-CAM)
- Pre-training AlexNetやVGGを用いて入力画像の推論を行う
- 対象となるクラスのみ1,それ以外を0として逆伝播を行う
- 各チャンネルで勾配のGrobal Average Pooling(GAP)を計算し,それを重みとする
- 特徴マップの値に重みを掛け,足し合わせてReLUに通す
- Guided Grad-CAM
- Guided BackpropagationやDeconvolutionを用いることで高解像度でより物体を中心とした可視化を行える
- 既存のCNNモデルのアーキテクチャを変えずに提案手法を適用することができる
4. どうやって有効だと検証した?
PASCAL VOC2007のトレーニングセットでfine-tuningしたAlexNetとVGGを用いて,バリデーションセットで可視化結果を生成している.Deconvolution・Guided Backpropagationと提案手法を比較している.それぞれの手法で生成された可視化結果をクラウドソーシングを使って,正解率を出している.結果は提案手法が優れたパフォーマンスを出すものとなっている.
5. 議論はあるか?
-
各畳み込み層についてGrad-CAMで可視化すると,最終の畳み込み層の出力が可視化に適していることがわかる

-
分類問題で分類に失敗したサンプルを可視化している

-
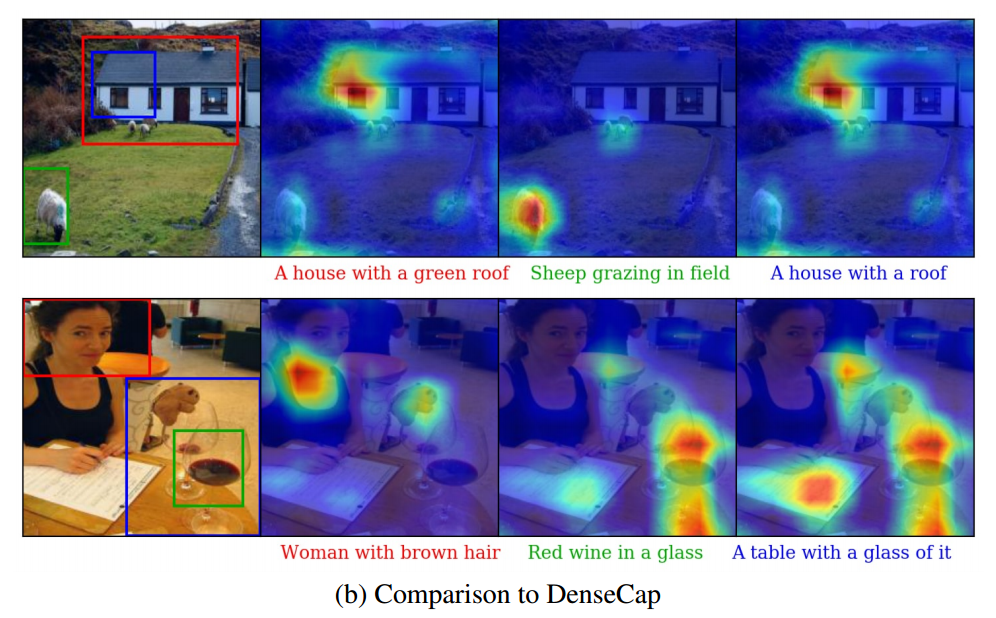
画像のキャプション生成タスクに対して適用

-
画像に対する質問応答タスクに対して適用
6. 次に読むべき論文はあるか?
Class Activation Mappingについて
Guided Backpropagationについて