Learning Deep Structured Semantic Models for Web Search using Clickthrough Data
1. どんなもの?
3層からなるNeural Networkを用いて検索クエリとクリックされた文書間の潜在的な意味を捉える,Deep Structured Semantic Model(DSSM)を提案.
2. 先行研究と比べてどこがすごいの?
クエリと文書のマッチングを行うものとして長い間研究されてきた潜在的意味モデルとして,Probabilistic Latent Semantic Analysis(PLSA)やLatent Dirichlet Allocation(LDA)などが知られている.また,近年発展を見せるDeep Learningを用いた潜在的意味モデルとして,深いネットワークのAutoEncoderを用いてクエリと文書をembeddし,潜在的な意味を取り出すものがある.
PLSAやLDAといったモデルは多くの場合,検索結果の評価とは違った目的関数を教師なしで学習するため,検索タスクにおいてはあまり良い結果を示さない.また語彙数が大きくなるについて行列計算や確率分布の推定コストがとても大きくなる.Deep AutoEncoderを用いた手法についても,語彙数が大きくなってしまうと計算コストが増えてしまう問題点がある.
本研究では教師あり学習の枠組みでクエリに対する文書の順位を学習する.また「Word Hashing」という語彙が大きくなっても扱えるような手法を提案している.
3. 技術や手法の”キモ”はどこにある?
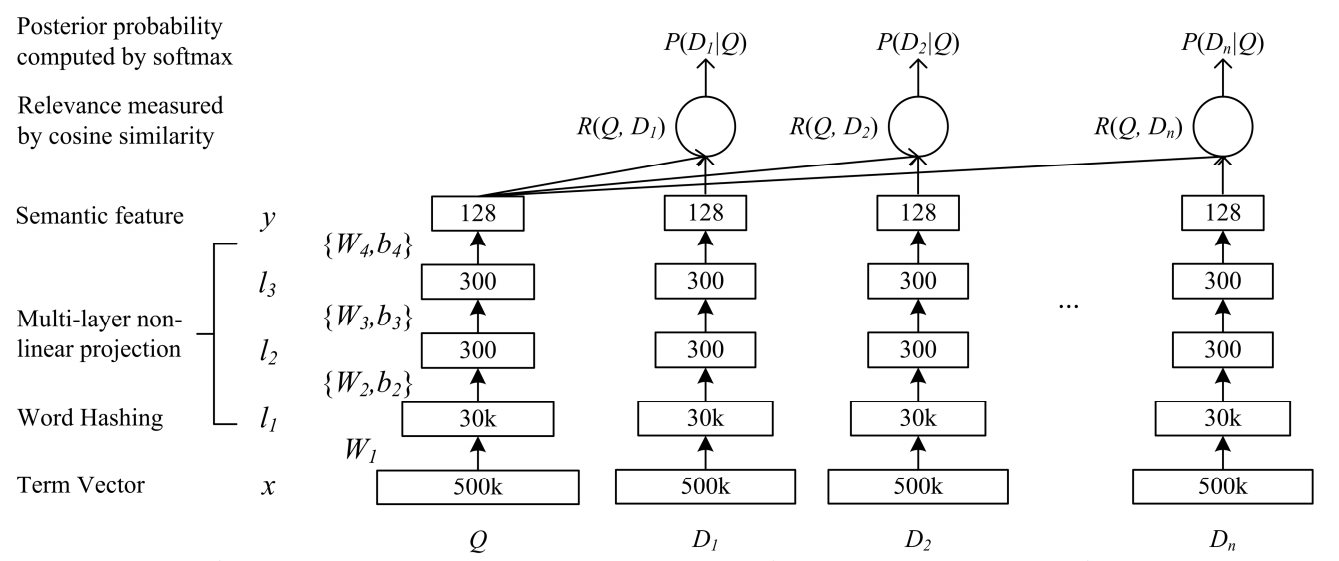
- 3層からなるDeep Neural Network(DNN)
- Term VectorからWordHashingするときに掛ける重みは学習させない
- 活性化関数にはtanhを使用
- Word Hashing
- 高次元のbag-of-words表現の次元を削減できる
- n-gramベースの変換
- 「good」が与えられた場合
- 最初と最後に#をつける (#good#).
- 文字n-gramにする.今回はtri-gramが使われている (#go, goo, ood, od#).
- これにより語彙数500,000のベクトル表現が30,000程度のベクトル表現にまで次元削減できる.
- トレーニングしたDNNにクエリと文書を通して得られるベクトルでコサイン類似度を取ることで関連性を得られる
4. どうやって有効だと検証した?
実際の検索エンジンのクエリログ16,510個を用いて実験が行われている.それぞれのクエリは15個の文書に紐付いている.各クエリと文書の関連度を0-4の5段階で人手でラベリングを行ったものを使用している.Normalized Discounted Cumulative Gain(NDCG)という評価基準で先行研究と本研究のスコアを比較している.すべての先行研究を上回るスコアを提案手法が出している.
5. 議論はあるか?
6. 次に読むべき論文はあるか?
クリックされた大量の文書について,教師あり学習の枠組みで潜在的な意味を捉えようとしている先行研究
Deep Learningを用いた潜在的な意味取得の先行研究
Normalize Discounted Cumulative Gainについて