Multi-Modal Fashion Product Retrieval
1. どんなもの?
ファッション商品の「画像情報」と「テキスト情報」を用いた、マルチモーダルな商品検索を可能にする。
2. 先行研究と比べてどこがすごいの?
従来の商品検索は画像のみにフォーカスされていて、なおかつ学習のためのデータセットを取得するのが難しかった。
本研究では、テキストデータのようなメタデータを併用し、画像とテキストを共通の特徴空間にマッピングしている。
3. 技術や手法の”キモ”はどこにある?
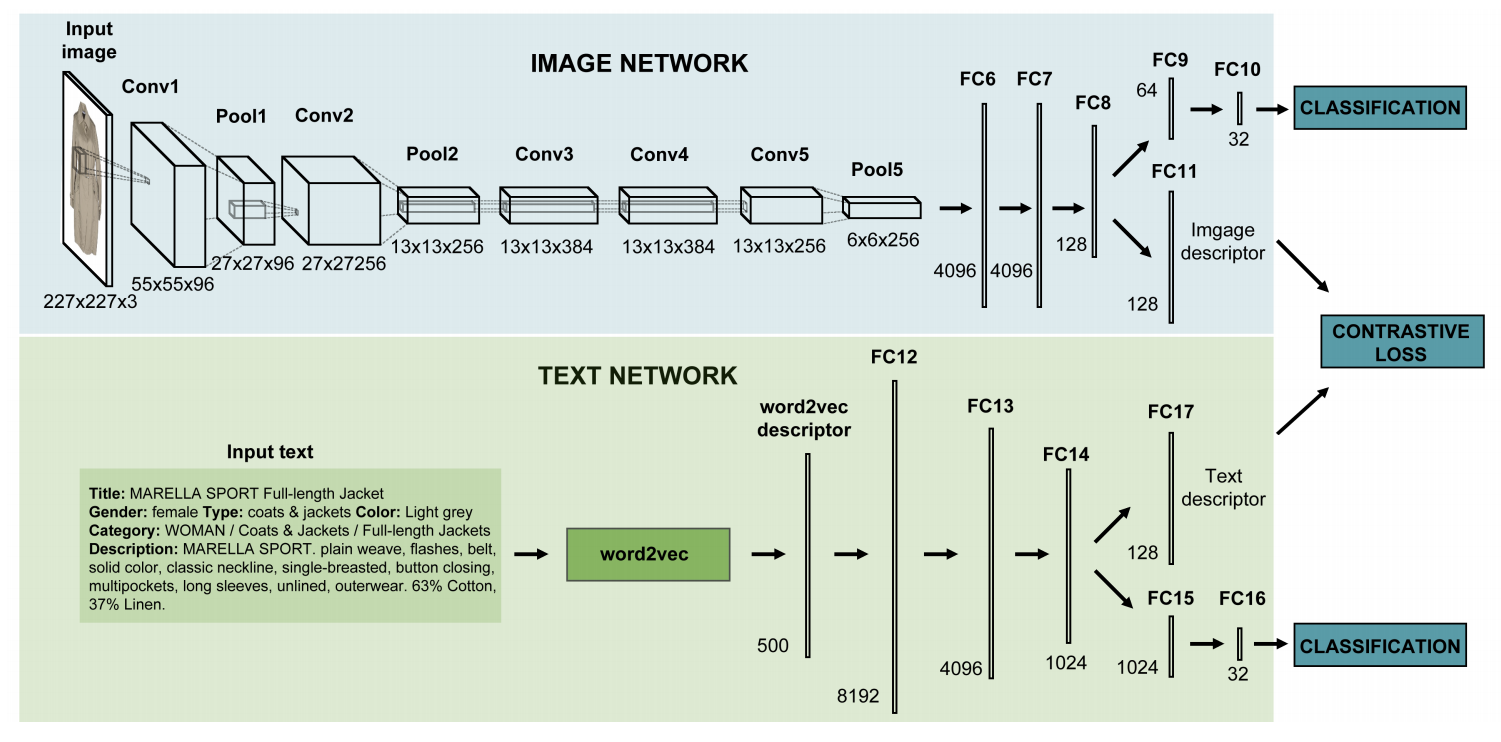
- 2つのNeural Network(NN)構造
- 画像用NN
- AlexNetをベースとしたConvolutional Neural Network(CNN)
- テキスト用NN
- 多層のNN
- 入力は学習済みword2vec
- 画像用NN
- Contrastive lossを用いた最適化
- 関連する画像-テキストのペアの距離を小さく
- 関連しない画像-テキストのペアの距離は大きく
4. どうやって有効だと検証した?
Eコマースサイトのファッション画像データセット431,841枚を対象に先行研究のKCCAと、本研究で入力するword2vecをBag-of-Wordsとした場合で比較を行っている。
あらかじめテストデータに対して本研究のモデルに通してembeddにしておく。テキストをクエリとして与えて正しい画像を得られるか、逆に画像をクエリとして与え正しいテキストを得られるかを評価している。
予測結果が正確に一致する位置を見て、各テストケースの中央値を計算したところ、先行研究のKCCAを大きく上回る優れたパフォーマンスを示した。
5. 議論はあるか?
- クエリにテキストを与えた場合に近い距離として現れる画像が以下のようになっている。

6. 次に読むべき論文はあるか?
先行研究のKCCAについて