画像生成 AI 入門: Python による拡散モデルの理論と実践#
![]()
Section 04. Key Researches Based on Non-Diffusion Models#
"非"拡散モデルベースの手法や、拡散モデルを支える基盤モデルについて紹介します。
Lecture 12. About CLIP (Contrastive Language-Image Pre-training)#
CLIP モデルのダウンロードと実行、任意の画像とテキスト入力の類似度計算、zero-shot 画像分類の実行方法を紹介します。
セットアップ#
GPU が使用できるか確認#
本 Colab ノートブックを実行するために GPU ランタイムを使用していることを確認します。CPU ランタイムと比べて画像生成がより早くなります。以下の nvidia-smi コマンドが失敗する場合は再度講義資料の GPU 使用設定 のスライド説明や Google Colab の FAQ 等を参考にランタイムタイプが正しく変更されているか確認してください。
!nvidia-smi
Wed Jun 21 12:18:05 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.85.12 Driver Version: 525.85.12 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 |
| N/A 45C P8 9W / 70W | 0MiB / 15360MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
利用する Python ライブラリをインストール#
今回は diffusers は使いません。その代わりに diffusers でも使われていて、diffusers をメンテナンスしている huggingface 社の transformers を使用します。
!pip install transformers
Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/
Collecting transformers
Downloading transformers-4.30.2-py3-none-any.whl (7.2 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 7.2/7.2 MB 97.7 MB/s eta 0:00:00
?25hRequirement already satisfied: filelock in /usr/local/lib/python3.10/dist-packages (from transformers) (3.12.0)
Collecting huggingface-hub<1.0,>=0.14.1 (from transformers)
Downloading huggingface_hub-0.15.1-py3-none-any.whl (236 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 236.8/236.8 kB 32.6 MB/s eta 0:00:00
?25hRequirement already satisfied: numpy>=1.17 in /usr/local/lib/python3.10/dist-packages (from transformers) (1.22.4)
Requirement already satisfied: packaging>=20.0 in /usr/local/lib/python3.10/dist-packages (from transformers) (23.1)
Requirement already satisfied: pyyaml>=5.1 in /usr/local/lib/python3.10/dist-packages (from transformers) (6.0)
Requirement already satisfied: regex!=2019.12.17 in /usr/local/lib/python3.10/dist-packages (from transformers) (2022.10.31)
Requirement already satisfied: requests in /usr/local/lib/python3.10/dist-packages (from transformers) (2.27.1)
Collecting tokenizers!=0.11.3,<0.14,>=0.11.1 (from transformers)
Downloading tokenizers-0.13.3-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (7.8 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 7.8/7.8 MB 123.9 MB/s eta 0:00:00
?25hCollecting safetensors>=0.3.1 (from transformers)
Downloading safetensors-0.3.1-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (1.3 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.3/1.3 MB 88.5 MB/s eta 0:00:00
?25hRequirement already satisfied: tqdm>=4.27 in /usr/local/lib/python3.10/dist-packages (from transformers) (4.65.0)
Requirement already satisfied: fsspec in /usr/local/lib/python3.10/dist-packages (from huggingface-hub<1.0,>=0.14.1->transformers) (2023.4.0)
Requirement already satisfied: typing-extensions>=3.7.4.3 in /usr/local/lib/python3.10/dist-packages (from huggingface-hub<1.0,>=0.14.1->transformers) (4.5.0)
Requirement already satisfied: urllib3<1.27,>=1.21.1 in /usr/local/lib/python3.10/dist-packages (from requests->transformers) (1.26.15)
Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.10/dist-packages (from requests->transformers) (2022.12.7)
Requirement already satisfied: charset-normalizer~=2.0.0 in /usr/local/lib/python3.10/dist-packages (from requests->transformers) (2.0.12)
Requirement already satisfied: idna<4,>=2.5 in /usr/local/lib/python3.10/dist-packages (from requests->transformers) (3.4)
Installing collected packages: tokenizers, safetensors, huggingface-hub, transformers
Successfully installed huggingface-hub-0.15.1 safetensors-0.3.1 tokenizers-0.13.3 transformers-4.30.2
CLIP モデルの読み込み#
🤗 Huggingface transformers を使用して、 CLIP モデルによる zero-shot 画像分類(学習データには含まれていないような、完全に未知のデータを対象)に取り組みます。
以下、Interacting with CLIP を参考に動作を追っていきます。ここではまず初めに CLIPModel で openai/clip-vit-large-patch14 を読み込みます。その後、読み込んだモデルに対応するテキストと画像の処理を行う CLIPProcessor を読み込みます。
今回使用する事前学習済み CLIP モデル以外にも様々なものが huggingface hub 上で見つけることができます。
from transformers import CLIPModel, CLIPProcessor
model_id = "openai/clip-vit-large-patch14"
# CLIP モデルの読み込み
model = CLIPModel.from_pretrained(model_id)
# モデルを推論モードにする
# このとき dropout を無効化したり、batch normalization の動作を推論用にする
model.eval()
# CLIP 用の前処理 pipeline の読み込み
processor = CLIPProcessor.from_pretrained(model_id)
`text_config_dict` is provided which will be used to initialize `CLIPTextConfig`. The value `text_config["id2label"]` will be overriden.
読み込んだモデルのパラメータ数、入力画像の解像度、入力テキストの最大長、語彙数を確認します。
import numpy as np
print(f"Model parameters: {sum([int(np.prod(p.shape)) for p in model.parameters()]):,}")
print(f"Input resolution: {model.config.vision_config.image_size}")
print(f"Context length: {processor.tokenizer.model_max_length}")
print(f"Vocab size: {model.config.text_config.vocab_size:,}")
Model parameters: 427,616,513
Input resolution: 224
Context length: 77
Vocab size: 49,408
CLIPProcessor について#
CLIP は画像とテキストを扱うマルチモーダルモデルです。それぞれのモダリティを適切に入力できるように、CLIPProcessor を使用して統一的にマルチモーダルデータを扱います。
以下は CLIPProcessor の概要です。画像の前処理を司る CLIPImageProcessor とテキストの前処理を司る CLIPTokenizerFast が含まれています。
processor
CLIPProcessor:
- image_processor: CLIPImageProcessor {
"crop_size": {
"height": 224,
"width": 224
},
"do_center_crop": true,
"do_convert_rgb": true,
"do_normalize": true,
"do_rescale": true,
"do_resize": true,
"feature_extractor_type": "CLIPFeatureExtractor",
"image_mean": [
0.48145466,
0.4578275,
0.40821073
],
"image_processor_type": "CLIPImageProcessor",
"image_std": [
0.26862954,
0.26130258,
0.27577711
],
"resample": 3,
"rescale_factor": 0.00392156862745098,
"size": {
"shortest_edge": 224
}
}
- tokenizer: CLIPTokenizerFast(name_or_path='openai/clip-vit-large-patch14', vocab_size=49408, model_max_length=77, is_fast=True, padding_side='right', truncation_side='right', special_tokens={'bos_token': AddedToken("<|startoftext|>", rstrip=False, lstrip=False, single_word=False, normalized=True), 'eos_token': AddedToken("<|endoftext|>", rstrip=False, lstrip=False, single_word=False, normalized=True), 'unk_token': AddedToken("<|endoftext|>", rstrip=False, lstrip=False, single_word=False, normalized=True), 'pad_token': '<|endoftext|>'}, clean_up_tokenization_spaces=True)
CLIPImageProcessor による画像処理#
CLIPProcessor に含まれる画像処理機構 CLIPImageProcessor の動作を確認します。まずはサンプルとなる画像をダウンロードします。ここでは stable diffusion 本家レポジトリから画像を借りました。
import requests
from PIL import Image
image = Image.open(requests.get("https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/txt2img/000002025.png", stream=True).raw)
image

ダウンロードしたサンプル画像は 1024 x 512 の解像度を有しています。CLIP の入力解像度は 224 x 224 であるため、この画像はリサイズされるべきです。
image.size
(1024, 512)
CLIPImageProcessor の機能を使って CLIP の入力に合うように前処理します。ここでは CLIPProcessor の images 引数に対象の画像を渡すことで、内部的に CLIPImageProcessor を用いて処理を行います。
output = processor(images=image, return_tensors="pt")
output
{'pixel_values': tensor([[[[ 1.7260, 0.3391, -0.3908, ..., 0.9376, 1.0106, 1.1566],
[ 1.7406, 0.7917, -0.3616, ..., 0.9230, 0.9668, 1.0690],
[ 1.7114, 1.4194, -0.0550, ..., 0.8938, 0.9084, 1.0252],
...,
[-1.4565, -1.3689, -1.5003, ..., -1.6609, -1.6317, -1.5441],
[-1.5149, -1.4419, -1.4711, ..., -1.6463, -1.6025, -1.4565],
[-1.4857, -1.4711, -1.4273, ..., -1.6463, -1.6025, -1.6025]],
[[ 2.0449, 1.1294, 0.4540, ..., 1.6847, 1.7297, 1.8348],
[ 2.0299, 1.5046, 0.4841, ..., 1.6847, 1.7147, 1.8047],
[ 2.0149, 1.9398, 0.8442, ..., 1.6697, 1.6997, 1.8047],
...,
[-1.3169, -1.1818, -1.3469, ..., -1.6170, -1.5570, -1.4820],
[-1.3169, -1.2118, -1.3019, ..., -1.6170, -1.5420, -1.3019],
[-1.2568, -1.1818, -1.2568, ..., -1.5870, -1.4970, -1.4219]],
[[ 2.0037, 1.2785, 0.7523, ..., 1.6909, 1.7051, 1.8046],
[ 2.0321, 1.5771, 0.7523, ..., 1.6909, 1.6909, 1.7904],
[ 2.0037, 1.9184, 1.0510, ..., 1.6766, 1.6909, 1.7762],
...,
[-1.0678, -0.9256, -1.0536, ..., -1.3096, -1.2811, -1.1958],
[-1.0678, -0.9541, -1.0394, ..., -1.2954, -1.2527, -1.0394],
[-1.0252, -0.9541, -0.9967, ..., -1.2811, -1.2100, -1.1532]]]])}
辞書型の output に含まれている pixel_values が前処理済みの画像です。以下のようにしてデータのサイズを確認すると、CLIP の入力に適した 224 x 224 のサイズになっていることがわかります。
output["pixel_values"].size()
torch.Size([1, 3, 224, 224])
CLIPTokenizer による言語処理#
CLIPProcessor に含まれる言語処理機構 CLIPTokenizer の動作を確認します。ここでは CLIPProcessor の text 引数の対象のテキストを渡すことで、内部的に CLIPTokenizer を用いてテキストをトークンに分割します。
output = processor(text="Hello world", return_tensors="pt")
output
{'input_ids': tensor([[49406, 3306, 1002, 49407]]), 'attention_mask': tensor([[1, 1, 1, 1]])}
辞書型の output には、分割結果はそれぞれトークンの ID 列に変換され、input_ids というキーで格納されます。attention_mask というキーは、可変長のテキストに対応するための mask を表しています。長さが異なるテキストが processor に入力されたときに、padding 部分に mask するように 0/1 の値が返ってきます。
トークンの ID 列である input_ids は、processor のデコード機能を使って文字列に戻すことができます。output はバッチを想定したデータ構造(input_ids のサイズが (batch_size, sequence_length))になっているため、以下では processor.batch_decode を使用してデコードしています。
processor.batch_decode(output["input_ids"])
['<|startoftext|>hello world <|endoftext|>']
CLIP では大文字・小文字を区別しない tokenizer を使用しているため、大文字だったところが小文字になっている点を除いては、もともとのテキストを復元できているように見えます。
CLIP で使用している tokenizer を始め、多くの tokenizer は学習用にテキストやセンテンスの始めを示す <|startoftext|> や <BOS> (begin of sentence) といったトークンや、テキストの終わりを示す <|endoftext|> や <EOS> (end of sentence) といったトークンを自動的に挿入します。
画像とテキストのセットアップ#
以下、8枚の画像とそのテキストキャプションを CLIP モデルに与えて、対応する特徴ベクトルの類似度を比較していきます。
再度確認ですが、CLIP の tokenizer は大文字・小文字を区別しないので、以下のようにざっくりとした文章を自由に記述可能です。
#
# 使用する skimage の画像とその説明文
#
descriptions_dict = {
"page": "a page of text about segmentation",
"chelsea": "a facial photo of a tabby cat",
"astronaut": "a portrait of an astronaut with the American flag",
"rocket": "a rocket standing on a launchpad",
"motorcycle_right": "a red motorcycle standing in a garage",
"camera": "a person looking at a camera on a tripod",
"horse": "a black-and-white silhouette of a horse",
"coffee": "a cup of coffee on a saucer"
}
skimage から画像データを取得します。
import os
import skimage
from more_itertools import sort_together
from PIL import Image
original_imgs = []
original_txts = []
# skimage から .png か .jpg な画像のパスを習得する
filenames = [
filename for filename in os.listdir(skimage.data_dir)
if filename.endswith(".png") or filename.endswith(".jpg")
]
for filename in filenames:
name, _ = os.path.splitext(filename)
if name not in descriptions_dict:
continue
# 画像の読み込み
image_path = os.path.join(skimage.data_dir, filename)
image = Image.open(image_path).convert("RGB")
original_imgs.append(image)
text = descriptions_dict[name]
original_txts.append(text)
# 画像とテキストの数があっているか確認
assert len(original_txts) == len(original_imgs)
# テキストの文字列をベースに、テキストと画像のリストをソートする
original_txts, original_imgs = sort_together((original_txts, original_imgs))
読み込んだ画像とテキストのペアを確認してみます。
import matplotlib.pyplot as plt
nrows = 2; ncols = 4
fig, axes = plt.subplots(nrows=nrows, ncols=ncols, figsize=(16, 5))
for i in range(nrows):
for j in range(ncols):
axes[i][j].imshow(original_imgs[i * ncols + j])
axes[i][j].axis("off")
axes[i][j].set_title(original_txts[i * ncols + j], fontsize=10)

特徴量の構築#
CLIP モデルに画像とテキストを入力するため、CLIPProcessor を使用します。この processor は煩雑な複数のモダリティの前処理を以下の一行で完了します。
inputs = processor(text=original_txts, images=original_imgs, padding="max_length", return_tensors="pt")
inputs
{'input_ids': tensor([[49406, 320, 1449, 268, 537, 268, 1579, 26149, 539, 320,
4558, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407],
[49406, 320, 1937, 539, 2453, 525, 320, 42272, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407],
[49406, 320, 11909, 1125, 539, 320, 36145, 2368, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407],
[49406, 320, 2504, 539, 4160, 781, 10551, 9512, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407],
[49406, 320, 2533, 1312, 536, 320, 3934, 525, 320, 36141,
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407],
[49406, 320, 5352, 539, 550, 18376, 593, 518, 2151, 4859,
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407],
[49406, 320, 736, 10297, 2862, 530, 320, 8474, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407],
[49406, 320, 8383, 2862, 525, 320, 31168, 7601, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407, 49407,
49407, 49407, 49407, 49407, 49407, 49407, 49407]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0]]), 'pixel_values': tensor([[[[ 1.9303, 1.9303, 1.9303, ..., 1.9303, 1.9303, 1.9303],
[ 1.9303, 1.9303, 1.9303, ..., 1.9303, 1.9303, 1.9303],
[ 1.9303, 1.9303, 1.9303, ..., 1.9303, 1.9303, 1.9303],
...,
[ 1.9303, 1.9303, 1.9303, ..., 1.9303, 1.9303, 1.9303],
[ 1.9303, 1.9303, 1.9303, ..., 1.9303, 1.9303, 1.9303],
[ 1.9303, 1.9303, 1.9303, ..., 1.9303, 1.9303, 1.9303]],
[[ 2.0749, 2.0749, 2.0749, ..., 2.0749, 2.0749, 2.0749],
[ 2.0749, 2.0749, 2.0749, ..., 2.0749, 2.0749, 2.0749],
[ 2.0749, 2.0749, 2.0749, ..., 2.0749, 2.0749, 2.0749],
...,
[ 2.0749, 2.0749, 2.0749, ..., 2.0749, 2.0749, 2.0749],
[ 2.0749, 2.0749, 2.0749, ..., 2.0749, 2.0749, 2.0749],
[ 2.0749, 2.0749, 2.0749, ..., 2.0749, 2.0749, 2.0749]],
[[ 2.1459, 2.1459, 2.1459, ..., 2.1459, 2.1459, 2.1459],
[ 2.1459, 2.1459, 2.1459, ..., 2.1459, 2.1459, 2.1459],
[ 2.1459, 2.1459, 2.1459, ..., 2.1459, 2.1459, 2.1459],
...,
[ 2.1459, 2.1459, 2.1459, ..., 2.1459, 2.1459, 2.1459],
[ 2.1459, 2.1459, 2.1459, ..., 2.1459, 2.1459, 2.1459],
[ 2.1459, 2.1459, 2.1459, ..., 2.1459, 2.1459, 2.1459]]],
[[[-1.2229, -1.1937, -1.2083, ..., 1.1858, 1.2150, 1.2588],
[-1.2083, -1.1937, -1.2083, ..., 1.2442, 1.2296, 1.2150],
[-1.2083, -1.1937, -1.1937, ..., 1.2150, 1.0836, 0.9668],
...,
[ 1.7114, 1.7260, 1.7406, ..., 0.6895, 1.0398, 0.9084],
[ 1.7114, 1.7114, 1.7406, ..., 0.9960, 0.8647, 0.6895],
[ 1.7114, 1.7552, 1.7114, ..., 0.7917, 0.6311, 1.0398]],
[[-1.3619, -1.3319, -1.3619, ..., 0.1689, 0.1989, 0.2740],
[-1.3469, -1.3319, -1.3619, ..., 0.1989, 0.2289, 0.2289],
[-1.3469, -1.3319, -1.3319, ..., 0.2139, 0.1239, 0.0038],
...,
[ 1.2945, 1.3695, 1.4145, ..., -0.4764, -0.1463, -0.2063],
[ 1.3395, 1.3995, 1.4145, ..., -0.2063, -0.2063, -0.4614],
[ 1.3095, 1.3845, 1.3395, ..., -0.2663, -0.4614, -0.1913]],
[[-1.2527, -1.2385, -1.2527, ..., -0.4279, -0.3853, -0.3426],
[-1.2527, -1.2385, -1.2527, ..., -0.3853, -0.3568, -0.3284],
[-1.2669, -1.2385, -1.2527, ..., -0.3568, -0.3995, -0.4848],
...,
[ 0.8519, 0.9656, 1.0225, ..., -0.9256, -0.7266, -0.7692],
[ 0.9372, 1.0225, 1.0083, ..., -0.7408, -0.7692, -0.9256],
[ 0.9230, 1.0225, 0.9941, ..., -0.7977, -0.8545, -0.7692]]],
[[[-0.0259, -0.0113, 0.0471, ..., 0.5289, 0.5873, 0.6457],
[ 0.0471, -0.0259, 0.0909, ..., 0.6165, 0.6311, 0.5727],
[ 0.0617, -0.0259, 0.0909, ..., 0.6311, 0.5581, 0.5143],
...,
[ 0.9376, 0.9230, 0.9376, ..., 0.8355, 0.8063, 0.7479],
[ 0.9376, 0.9084, 0.9230, ..., 0.8355, 0.7771, 0.7333],
[ 0.9376, 0.9084, 0.9376, ..., 0.8209, 0.7771, 0.7333]],
[[-0.8066, -0.7316, -0.7016, ..., 0.0188, 0.0789, 0.1689],
[-0.7166, -0.7766, -0.6715, ..., 0.0939, 0.1389, 0.0789],
[-0.6865, -0.7766, -0.6415, ..., 0.1539, 0.0488, -0.0112],
...,
[ 0.5741, 0.5591, 0.5741, ..., 0.6191, 0.5891, 0.5291],
[ 0.5741, 0.5441, 0.5591, ..., 0.6191, 0.5591, 0.5291],
[ 0.5441, 0.5441, 0.5741, ..., 0.6041, 0.5591, 0.4991]],
[[-0.7834, -0.7123, -0.6412, ..., 0.1266, 0.1977, 0.2688],
[-0.6981, -0.7408, -0.6128, ..., 0.2120, 0.2546, 0.1835],
[-0.6555, -0.7266, -0.5844, ..., 0.2546, 0.1693, 0.1124],
...,
[ 0.5248, 0.4964, 0.5248, ..., 0.5817, 0.5532, 0.5106],
[ 0.5248, 0.4821, 0.5106, ..., 0.5675, 0.5390, 0.5248],
[ 0.5248, 0.4964, 0.5532, ..., 0.5817, 0.5532, 0.5248]]],
...,
[[[ 0.2953, -0.3616, 0.1931, ..., 0.0471, 0.0471, 0.0179],
[ 1.2588, 1.0252, 1.1420, ..., 0.0617, 0.0325, 0.0471],
[ 1.6530, 1.5362, 1.3172, ..., 0.0471, 0.0471, 0.0325],
...,
[ 0.9230, 0.9522, 0.8501, ..., -0.6828, -0.9018, -1.7923],
[ 0.9230, 0.8792, 0.6749, ..., -0.6390, -1.6755, -1.7923],
[ 0.8938, 0.7771, 0.4997, ..., -0.8434, -1.2667, -1.7923]],
[[ 0.3190, -0.2963, 0.2589, ..., 0.0338, 0.0338, 0.0038],
[ 1.2945, 1.0694, 1.2044, ..., 0.0038, 0.0038, 0.0038],
[ 1.6697, 1.5796, 1.3395, ..., 0.0188, 0.0188, 0.0038],
...,
[ 0.7692, 0.8292, 0.6792, ..., -0.7466, -0.8816, -1.7521],
[ 0.7842, 0.7392, 0.5141, ..., -0.6715, -1.6470, -1.7521],
[ 0.7692, 0.6191, 0.3190, ..., -0.8516, -1.2118, -1.7521]],
[[ 0.5959, 0.1977, 0.4253, ..., 0.1124, 0.1124, 0.0698],
[ 1.3638, 1.1789, 1.2216, ..., 0.0982, 0.0982, 0.0982],
[ 1.7193, 1.6340, 1.3780, ..., 0.1124, 0.1124, 0.0982],
...,
[ 1.0083, 1.0510, 0.8945, ..., -0.5559, -0.6697, -1.4802],
[ 1.0083, 0.9514, 0.6812, ..., -0.5275, -1.4091, -1.4802],
[ 0.9656, 0.8234, 0.4537, ..., -0.6555, -1.0394, -1.4802]]],
[[[-0.5806, -0.4054, -0.3470, ..., -0.0113, -0.0259, -0.0405],
[-0.5806, -0.8142, -0.8872, ..., -0.0550, -0.0405, -0.0405],
[-0.5952, -0.7412, -0.8288, ..., -0.0842, -0.0696, -0.0696],
...,
[ 0.6749, 0.7771, 0.8355, ..., 0.6165, 0.6165, 0.5873],
[ 0.7041, 0.7333, 0.7479, ..., 0.6165, 0.5873, 0.5581],
[ 0.6749, 0.6749, 0.7041, ..., 0.6311, 0.6019, 0.5727]],
[[-1.0617, -0.8516, -0.6715, ..., 0.0188, 0.0038, 0.0188],
[-1.0317, -1.3169, -1.4519, ..., 0.0188, 0.0038, 0.0188],
[-1.0617, -1.3169, -1.4369, ..., -0.0112, 0.0038, 0.0038],
...,
[ 0.6341, 0.7392, 0.7692, ..., 0.4540, 0.4390, 0.4090],
[ 0.6191, 0.6642, 0.6942, ..., 0.4390, 0.4390, 0.3790],
[ 0.6191, 0.6191, 0.6491, ..., 0.4540, 0.4390, 0.4090]],
[[-1.0821, -0.8830, -0.5844, ..., 0.2831, 0.2973, 0.2973],
[-1.0821, -1.2669, -1.3807, ..., 0.3257, 0.3399, 0.3257],
[-1.0963, -1.2811, -1.3807, ..., 0.2831, 0.2831, 0.2973],
...,
[ 0.6244, 0.7381, 0.7808, ..., 0.4679, 0.4253, 0.4253],
[ 0.6386, 0.6670, 0.6955, ..., 0.4537, 0.4395, 0.3826],
[ 0.6386, 0.6386, 0.6528, ..., 0.4679, 0.4537, 0.4110]]],
[[[-1.5003, -1.5003, -1.5003, ..., -1.5733, -1.6025, -1.6025],
[-1.5003, -1.5003, -1.5003, ..., -1.5733, -1.6025, -1.6025],
[-1.5003, -1.5003, -1.5003, ..., -1.5733, -1.6025, -1.5879],
...,
[ 1.1274, 1.7698, 1.6092, ..., -1.3689, -1.3689, -1.3835],
[ 1.1858, 1.2442, 0.4559, ..., -1.3835, -1.3835, -1.3981],
[ 0.9084, 0.3975, 0.2807, ..., -1.4273, -1.4273, -1.4127]],
[[-1.2118, -1.2118, -1.2118, ..., -1.3619, -1.3469, -1.3619],
[-1.2118, -1.2118, -1.2118, ..., -1.3469, -1.3469, -1.3619],
[-1.2118, -1.2118, -1.2118, ..., -1.3619, -1.3469, -1.3469],
...,
[ 1.1894, 1.8948, 1.6847, ..., -1.2869, -1.2869, -1.3019],
[ 1.2945, 1.3995, 0.5141, ..., -1.3019, -1.3019, -1.3169],
[ 0.9343, 0.4540, 0.3490, ..., -1.3169, -1.3169, -1.3319]],
[[-0.5986, -0.5986, -0.5986, ..., -0.8545, -0.8403, -0.8403],
[-0.5986, -0.5986, -0.5986, ..., -0.8403, -0.8261, -0.8261],
[-0.5986, -0.5986, -0.5986, ..., -0.8261, -0.8261, -0.8261],
...,
[ 0.9941, 1.8046, 1.6198, ..., -0.8688, -0.8688, -0.8830],
[ 0.8519, 0.9799, 0.2831, ..., -0.8830, -0.8830, -0.8972],
[ 0.4537, 0.0698, -0.0440, ..., -0.9114, -0.9114, -0.9114]]]])}
CLIPModel を利用して、画像特徴とテキスト特徴をそれぞれ計算します。
import torch
with torch.no_grad():
img_features = model.get_image_features(
pixel_values=inputs["pixel_values"],
)
txt_features = model.get_text_features(
input_ids=inputs["input_ids"],
attention_mask=inputs["attention_mask"],
)
コサイン類似度を計算する#
上記で得られた特徴量を正規化し、各ペアの内積を計算します。
img_features = img_features / img_features.norm(p=2, dim=-1, keepdim=True)
txt_features = txt_features / txt_features.norm(p=2, dim=-1, keepdim=True)
similarity = img_features @ txt_features.T
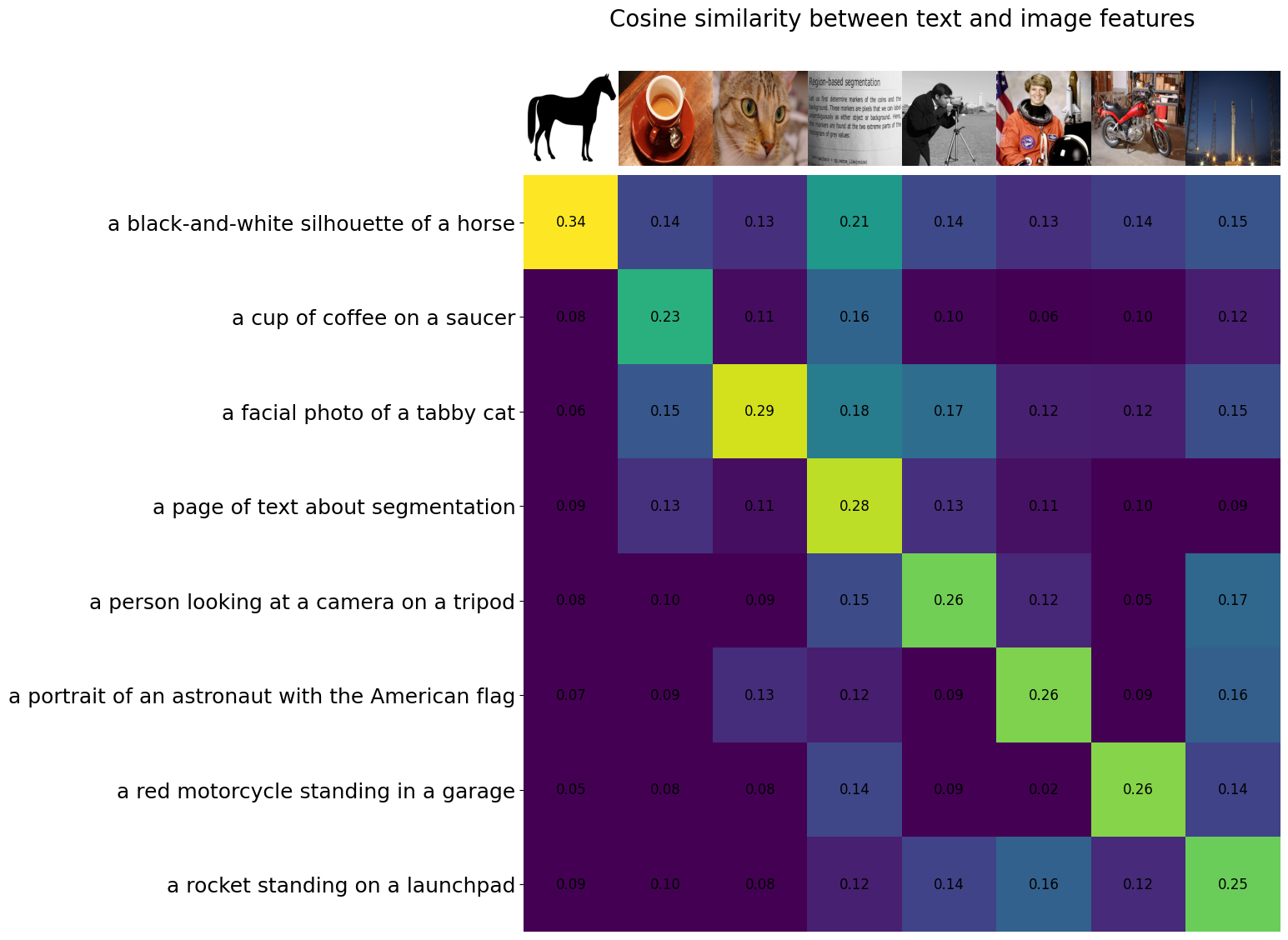
画像とテキスト、それぞれの類似度を以下のようにして可視化します。対角線上がもともと対応していた画像とテキストにおける類似度です。CLIP による特徴ベクトルを利用することで、画像とテキストの正しいペアの類似度が高くなっていることが確認できました。
assert len(original_imgs) == len(original_txts)
count = len(original_imgs)
fig, ax = plt.subplots(figsize=(20, 14))
ax.imshow(similarity, vmin=0.1, vmax=0.3)
ax.set_yticks(range(len(original_txts)), labels=original_txts, fontsize=18)
ax.set_xticks([])
for i, img in enumerate(original_imgs):
ax.imshow(img, extent=(i - 0.5, i + 0.5, -1.6, -0.6), origin="lower")
for x in range(similarity.shape[1]):
for y in range(similarity.shape[0]):
ax.text(x, y, f"{similarity[y, x]:.2f}", ha="center", va="center", size=12)
for side in ["left", "top", "right", "bottom"]:
plt.gca().spines[side].set_visible(False)
ax.set_xlim([-0.5, count - 0.5])
ax.set_ylim([count - 0.5, -2])
ax.set_title("Cosine similarity between text and image features", size=20)
Text(0.5, 1.0, 'Cosine similarity between text and image features')
Zero-shot 画像分類#
CLIP は追加学習なしで未知の画像を分類することが可能です。以下では CIFAR100 と呼ばれる 100 クラスの画像分類データセットを用いて CLIP の zero-shot 画像分類性能について見ていきます。
まずは torchvision を用いて CIFAR100 データセットを読み込みます。
from torchvision.datasets import CIFAR100
cifar100 = CIFAR100(os.path.expanduser("~/.cache"), download=True)
Downloading https://www.cs.toronto.edu/~kriz/cifar-100-python.tar.gz to /root/.cache/cifar-100-python.tar.gz
100%|██████████| 169001437/169001437 [00:13<00:00, 12737679.44it/s]
Extracting /root/.cache/cifar-100-python.tar.gz to /root/.cache
CLIP に入力するプロンプトとして、This is a photo of a {label} のようなテンプレート文を用意します。その後 CIFAR100 に存在するクラスでテンプレートを埋めた文のリストを得ます。
text_template = "This is a photo of a {label}"
text_descriptions = [text_template.format(label=label) for label in cifar100.classes]
上記で用意したテキストのリストを元に、CLIPProcessor である processor でトークンへ変換します。その後 CLIPModel でテキストトークン列からテキスト特徴ベクトルを取得します。最後に取得したテキストベクトルを正規化しておきます。
inputs = processor(text=text_descriptions, padding="max_length", return_tensors="pt")
with torch.no_grad():
txt_features = model.get_text_features(
input_ids=inputs["input_ids"],
attention_mask=inputs["attention_mask"],
)
txt_features = txt_features / txt_features.norm(p=2, dim=-1, keepdim=True)
画像とテキストの特徴ベクトルの内積を取り、そのスコアを 100 倍して softmax に通すことで、通常の分類モデルのような形で画像を分類できます。ここでは予測結果上位 5 件を選択しています。
txt_probs = (100 * img_features @ txt_features.T).softmax(dim=-1)
top_probs, top_labels = txt_probs.topk(5, dim=-1)
これまでに得られた zero-shot 画像分類結果を以下に可視化します。画像とそれに紐づくキャプションと、zero-shot 分類したときの予測結果上位 5 件を示しています。
nrows = 4; ncols = 4
fig = plt.figure(figsize=(16, 16))
plt.style.use("ggplot")
y = np.arange(top_probs.shape[-1])
for i, img in enumerate(original_imgs):
ax1 = fig.add_subplot(nrows, ncols, 2 * i + 1)
ax1.imshow(img)
ax1.axis("off")
ax1.set_title(original_txts[i], fontsize=10)
ax2 = fig.add_subplot(nrows, ncols, 2 * i + 2)
ax2.barh(y, top_probs[i])
plt.gca().invert_yaxis()
plt.gca().set_axisbelow(True)
ax2.set_yticks(y, [cifar100.classes[idx] for idx in top_labels[i]])
ax2.set_xlabel("Probability")
fig.subplots_adjust(wspace=0.5)
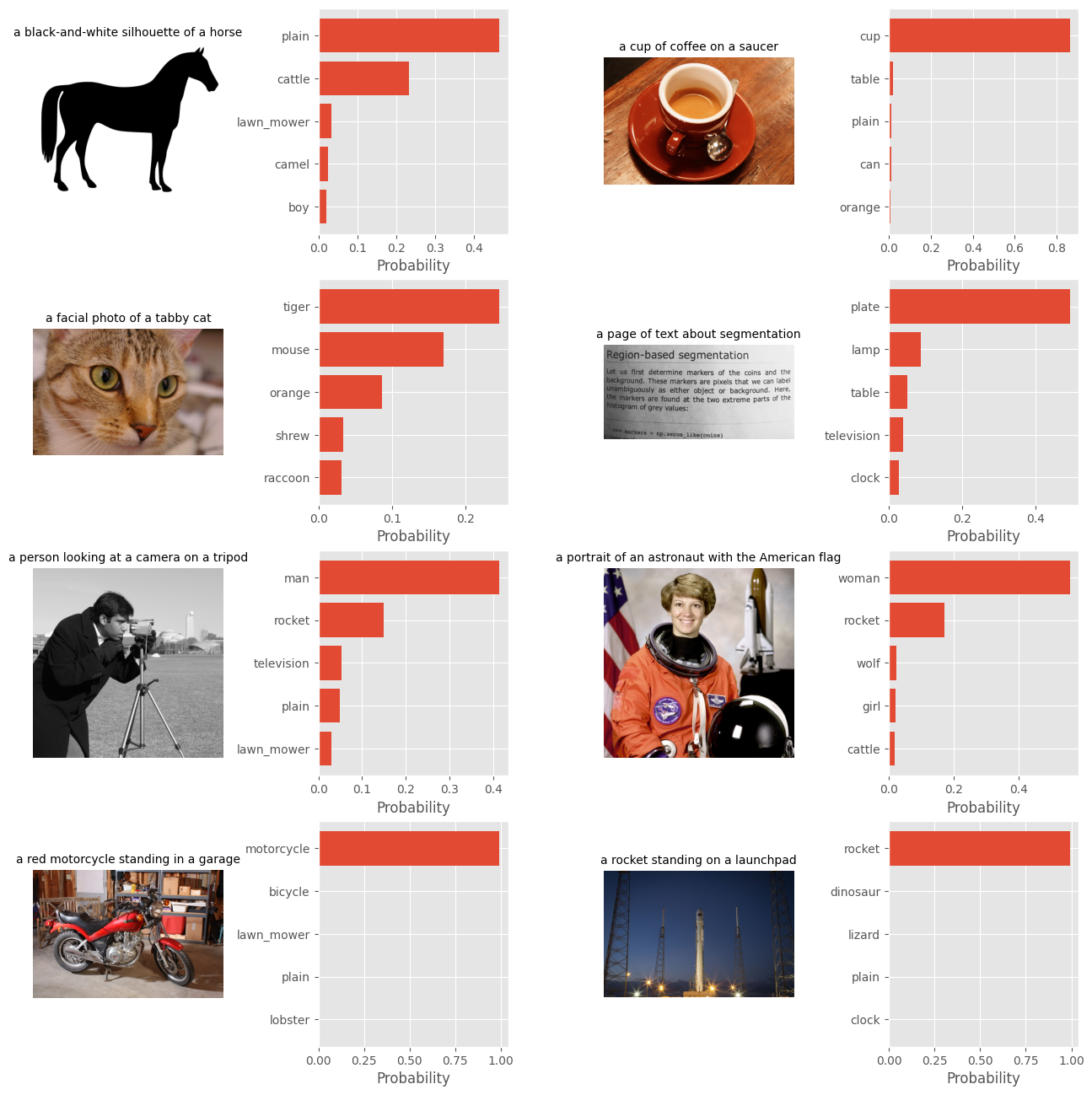
男 (man)・女 (woman) のレベルでは zero-shot で適切に予測が可能なように見えます。猫が虎として予測されてしまっているのは仕方がなさそうですね。カップやバイク、ロケットが高い確信度で予測が出力されているのは素晴らしいですね。